
これは Livesense Advent Calendar 2022 DAY 16 の記事です。
はじめに
私達のチームはbatonnというサービスを開発しています。 このサービスではWeb上で面接を録画したあと話者ごとに文字起こしをして面接を可視化できるように整形しています。 今回は文字起こしの高速化について行ったことを書きます。
文字起こしの大雑把な手順
文字起こしを実現するために提供されているサービスはいくつか存在しています。 有名どころではGPC、Azure、AWSが提供するAPIなどがありますがbatonnではこれらのAPIを利用して文字起こしを実現するシステムを構築しています。
- 音声データを何らかの方法で用意する
- 文字起こしAPIにリクエストを投げる
- 完了まで待つ
とても手軽に実現できますね! 我々は良い時代に生まれました。
実装にあたっての話
音声を用意してAPIにリクエストを投げて完了まで待ったら取得できるよねと言うのは簡単なのですがいくつか考える必要のあることがあります。
実際のサービスで動かすときに考えないといけないこと
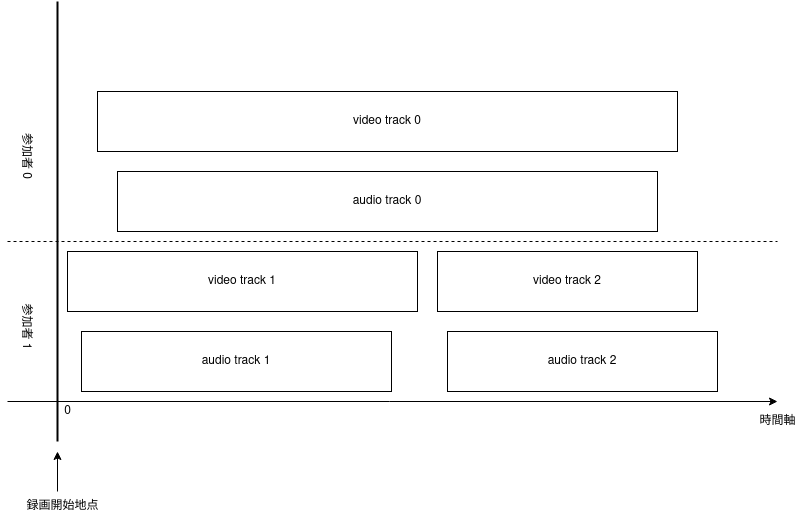
実際にサービスを作るためには録音する方法を用意する必要があります。 batonnではTwilio Programmable Videoを利用しています。 Twilioで録画をしたときaudio trackやvideo trackは独立して取得することができます。 またオンラインでの通話中にリロードをすると同一話者でもtrackが分断するようなことが発生します(図1)。 なので録画した音声を文字起こししたり動画を配信したりするときは時間を同期してうまい具合に結合してあげる必要があります。
batonnでの話
batonnでは面接を文字起こししています。 そして表示するときは話者ごとに分離されたテキストを表示しています(以後話者分離)。 話者分離を実現するにあたってどのように文字起こしを実現しているかというと、Twilioは参加者ごとにtrackが取得できるので、時間を同期させた上でエンコードし、文字起こしAPIで処理をしています。 話者ごとのデータを同期してエンコードすることはTwilio Composition API(以後Composition API)を利用すると手軽に実現できます。 Composition APIを利用して音声を結合するには問題があります。 Composition APIは内部的にqueue/workerになっていて計算機資源は世界中で共有して利用しています。 なので混雑しているときにjobを投げると長い時間待たされることがあります。 それがたとえ5分の音声を投げたとしても1時間ほど待たないと行けないことがあります。 できるだけ利用者に早く情報をお伝えしたいサービス提供側としては少し辛い問題です。
高速化を考える
というわけで高速化を考えます。 Composition APIは性質上情報を分割して投げてやれば高速化できるようなものではありません。 なので我々はCompositon APIを利用しない方法を考えることにしました。 Twilioは録画終了するとWebMのaudio trackとvideo trackを取得することができます。 audio trackをつなげることなく文字起こしを実行して後から時間の辻褄を合わせてしまえば良いのではないかと思いつきました。 そのためには各trackを同期するための時間を取得する必要があります。
trackが持っている情報について
Twilioが作るWebMをFFmpegを利用して調べるとstart_timeという情報があることがわかります。
次のようにコマンドを打つとjsonで動画の情報を出力できます。
$ ffprobe -v error -i ${INPUT_FILE_NAME} -show_streams -of json
今回ほしいのはstart_timeなのでjqにでも食わして取得すれば良いでしょう。
$ ffprobe -v error -i input.webm -show_streams -of json | jq -r .streams[].start_time 56.260000
ここで出てくるstart_timeはTwilioが録画開始をしてから実際のtrackが開始される時間です(図2)。

Twilioのaudio trackを扱うときの注意点
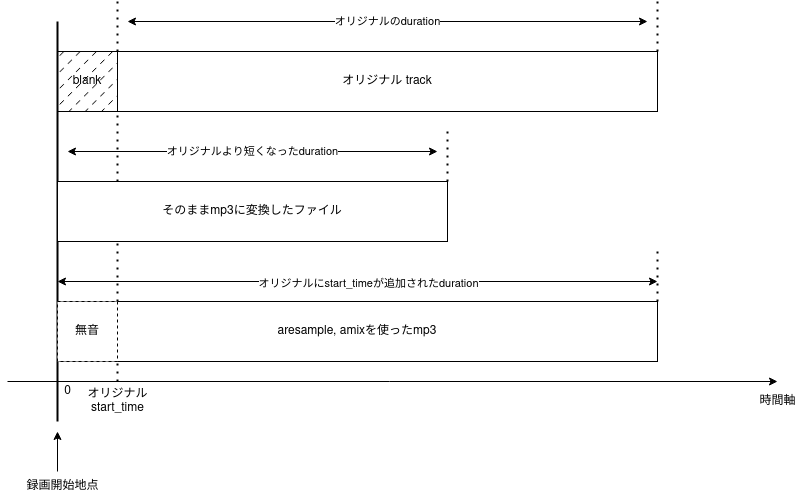
Twilioのaudio trackを別のformatに変換しようとすると不思議なことが発生します。 例えばmp3に変換をするとしましょう。
$ ffmpeg -i input.webm output.mp3 $ ffmpeg -i input.webm 2>&1 | grep "Duration" Duration: 00:06:21.45, start: 56.260000, bitrate: 11 kb/s $ ffmpeg -i output.mp3 2>&1 | grep "Duration" Duration: 00:02:35.18, start: 0.023021, bitrate: 128 kb/s
6分21秒のファイルが2分35秒になってしまいましたね。
とくに何もしないと長さが変わります(図3)。
この現象は文字多しAPIにそのままTwilioの出力するWebMをそのまま投げても発生します。
あとから動画に字幕をつけようとしたときにずれてしまうようなことが起きるわけですね。
なので対策をしてあげる必要があります。
FFmpegのaresampleとamixfilterを利用することで対策ができます。
$ ffmpeg -copyts -i input.webm -filter_complex "[0]aresample=async=1:first_pts=0[a0];[a0]amix=inputs=1" output.mp3 $ ffmpeg -i output.mp3 2>&1 | grep "Duration" Duration: 00:07:17.74, start: 0.023021, bitrate: 128 kb/s
一見6分21秒から7分17秒に伸びているように見えますがstart_pts分の56秒を無音で埋めているので適宜カットすると揃います。 前処理がすべて終わったのであとは文字起こしAPIで処理をしてあげるとずれていない文字起こしが完成します。
最終的にどうなったか
Composition APIを置き換えた結果30分~1時間前後処理時間がかかっていたものが5分前後で完了できるようになりました。