
データプラットフォームグループの富士谷です。普段は弊社の機械学習基盤であるLivesense Brainの運用・開発を行っています。 機械学習基盤とは実際のところ、機械学習に関わる複雑な処理にも耐えられるバッチ処理・Webアプリケーション実行環境であり、Livesense Brainでは機械学習に限らず、社内外向けに様々なシステムを構築しています。
さて、今回は、少し前に取り組んだ、音声認識結果の文字起こしからのキーワード抽出の取り組みについて、簡単にご紹介したいと思います。
はじめに
リブセンスでは新規事業の1つとして、オンライン面接ツールbatonnの開発に取り組んでおり、昨年β版をリリースしました。
batonnは、オンライン面接を実施できることに加え、ブラックボックスになりがちな面接を、録画と文字起こしによって可視化することで、効率的な振り返りや引き継ぎをサポートするツールです。 録画や文字起こしを見れば、面接に参加していた人は「あのときどんな話をしたか」をもとに申し送りを書くことができますし、次の面接の担当者は、面接の雰囲気や内容の詳細を把握することができます。
しかし、面接時間は通常1時間程度はあり、その録画や文字起こしの分量は多く、面接の参加者であってもすぐに目的となる動画の位置や文字起こしを見つけ出すことは簡単ではありません。この問題を軽減するには、いろいろな方法が考えられます。一つには例えば、「10:00〜11:00: プロダクト」「11:00〜12:00: チーム」というように、目次(インデックス)となるようなキーワードを自動的に文字起こしから抽出できれば、「ああ、面接開始から10分後くらいにプロダクトについて話したんだな」と把握しやすくなりそうです。
ということで、文字起こしから時間ごとのキーワードを抽出する方法を検討しました。
このキーワードは、例えば「自己紹介」や「質疑応答」「前職の経歴」など、より抽象度が高いカテゴリーのようなものであると、動画の目次やチャプター名としてより理解しやすいですが、このような抽象度が高いキーワードを取得(生成)するのは難易度が非常に高そうです。そこで、今回はある面接の文字起こし(テキストとタイムスタンプ)のみを使い、実際に文字起こしに出現した単語のみをキーワードの候補としました。
キーワード抽出の既存ツール
既存のツールやサービスで目的を満たせないか、簡単に調査しました。 例えば、Azure には、Azure Video Analyzer for Mediaという、動画分析を行うSaaSがあります。このサービスでは、文字起こしに加えキーワード抽出してくれる機能があり、希望に近いものでした。Azure Cognitive Service for Languageのキーフレーズ抽出も同様です。 しかし、これを試した当時(2021年の下半期頃)は、あまりキーワードとして適切ではないものが出てきたり、動画全体のキーワードが出力され動画の目次に使うには不便だったりと、採用には至りませんでした。
キーワード抽出のアルゴリズムの実装として pke というOSSがあります。これも簡単に試してみましたが、やはり文書全体からキーワードを抽出するアルゴリズムが中心で、今回の目的からは少し外れていました。
スライディングウインドウによるキーワード抽出
既存のツールでは満足できなかったので、スライディングウィンドウを使って出現回数を集計するシンプルな方法をまずは実装してみました。 これは、例えば、文字起こし全体をそのタイムスタンプを使って10分割し、それぞれのウインドウごとに単語の出現回数が多いものをキーワードとして出力する、というものです。 頻度ベースなので、比較的短い文字起こしでも有用ですし、動作も軽量です。 分割数を増減することで、大雑把にしたり、細かくしたりと、キーワードの粒度(個数)を容易に変えることができます。 しかし、一方で、ウインドウ幅やスライドの仕方によって、出現するキーワードが大きく変わってしまう課題がありました。
カーネル密度推定によるキーワード抽出
そこで、上述の課題を解決するため、カーネル密度推定を使うことにしました。 カーネル密度推定は、ざっくりいうと、いくつかの標本点から、その元となる確率密度を推定する方法です。これを使うことで、ウインドウ幅などに依存せずに、時間ごとの単語の出現確率がなめらかな形で得られます。もちろん、この方法にもいくつかパラメータがあるので、これに依存して出力結果は変わりますが、スライディングウィンドウであった出現するキーワードが大きく変わってしまう課題は緩和されます。
実装としてscikit-learnにKernelDensityがあり、高速に動作し、ほんの数行で手軽に試すことができます。 密度推定についてもわかりやすく記載されています。
これを使って、キーワードを抽出します。 大まかな流れは以下のとおりです。 まずは、文字起こしから形態素解析器で目的とする単語(名詞)を抽出したあと、文字起こしのタイムスタンプを使って、単語の出現位置(面接開始から何秒後に発せられたか)を取得します。 続いて、こんな感じのコードでカーネル密度推定します。
kde = KernelDensity(kernel="gaussian", bandwidth=bandwidth).fit(np.array(data))
log_density = kde.score_samples(time_array)
data には、 [1, 4, 10] というような単語の出現位置が保持されており、time_arrayは、KernelDensity.score_samples の仕様に合うように作った、0秒〜動画の録画時間 となるようなn行1列のnumpy.arrayです。
その後、他の単語と比較するために、カーネル密度推定で得られた値が単語が出現した位置で1となるように補正します。
score = np.exp(log_density) * len(data) * math.sqrt(2 * math.pi * bandwidth ** 2)
このスコアを、一定回数以上出現したすべての単語に対し取得します。すべてひとまとめに表示すると例えばこんな感じになります。
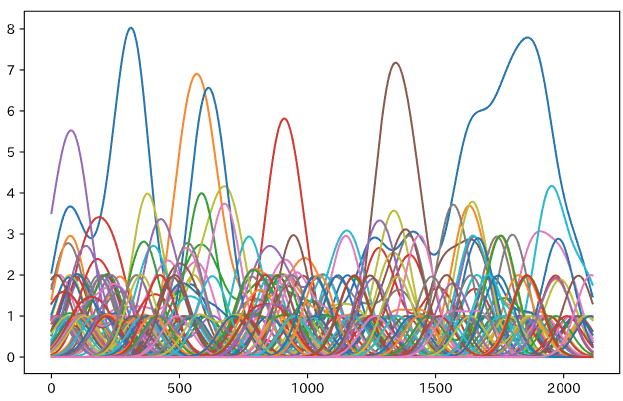
横軸は時刻(秒)で、縦軸は出現頻度(回)です。なにか後半によく出てくる単語が2つあるな、くらいはわかりますが、これだと何がなんだかよくわからないので、その後、時刻ごとにスコアが一定以上であり、さらに上位2件程度の単語を取り出します。これで、出現位置(秒)ごとのキーワードが得られます。ただ、このままだと、データ量が膨大になりすぎるので、(単語、出現開始時刻、出現終了時刻)の三つ組のデータに変換してからフロントエンドに渡します。このとき、想定以上に細かく区切られてしまったもの除外するといったいくつかの工夫を行っています。
このデータをうまく可視化してあげると以下のようになります。この結果は、社内で行った模擬面接の結果です(上のグラフとは別のデータです)。

これを見るだけでも、なんとなく話された内容がわかるのではと思います。 興味を持った箇所をクリックするとその前後の動画や文字起こしに移動して詳細を見ることができます。
まとめ
今回は、カーネル密度推定を使ったキーワードの抽出についてご紹介しました。キーワードを動画や文字起こしの目次(インデックス)として使うと、「どこで何を話したか」の理解に役立ちます。 ここではご紹介できませんでしたが、キーワードの抽出結果は、文字起こしの品質に依存するために、これを高めるような工夫を入れています。また、APIはCloudRunやfastapiなどを使って実装しています。
キーワード抽出の方法はカーネル密度推定以外にも様々あるでしょう。また、評価についても定性的なものに留まっています。データセットをうまく作ることができれば、選択肢も広がると考えています。今後も継続的に改良策を検討していければと思っています。
batonnには効率的な引き継ぎを実現するために他にも様々な機能が搭載されています。もし、batonnに興味あれば、無料トライアルもありますので、ぜひサイトからお問い合わせください。