
こちらは Livesense Advent Calendar 2025 DAY 17 の記事です。
転職会議のエンジニアです。 フロントエンドの品質を担保するために行っている取り組みの一つをご紹介します。
3 行で
- Visual Regression Test (VRT) の結果が見づらいから AI に要約させてみた
- 概ね良い感じだが、推論の難易度が高いのかたまにイマイチな報告をするケースがある
- Chain-of-Thought (CoT / 思考の連鎖) プロンプティングを使ってチューニングしてみる
Visual Regression Test (VRT) って?
VRT は Pull Request などによるデザイン崩れなどの不具合を変更前後の画面を比較することで検出する自動テストの一つです。

転職会議では Playwright + Storybook + msw で VRT を実現しています。複数のブラウザエンジンで PC & モバイルレイアウトを多数のページを モック API を通してサクッとチェックできるので、主に以下のようなケースで非常に頼りになります。
- 共通のコンポーネントやモジュールを修正するとき
- コンポーネントの共通化するとき
- その他ロジックなどのリファクタリング
しかし、VRT は結果が見づらいのです
上の例を見て、すぐに フォームの入力欄の途中で折り返してしまい 2 段になってしまっている。 と理解できる人は少ないと思います。高さの変化が起こると大抵こんなふうに真っ赤っ赤になってしまい、どこが変化したのかわかりづらくなってしまうからです。前後画像をタブを 2 つ開いて切り替えまくったり、Swipe スライダーを左右にスコスコして、ようやくビジュアル変化を言語化できるまで理解することができます。
また、意図的な変更も含めて差分として検知するため、デグレの有無は見づらい結果から人間がしっかり目で見て判断する必要があります。 そのような性質を持つテストなので、崩れている事に気づかずに Approve してしまう開発者もいます。なので、VRT に慣れているレビュアーがフォローする必要があります。
この、わかりづらい結果を翻訳してレビュイーに わかりやすく伝えるコメント作成が地味に面倒 なのです。

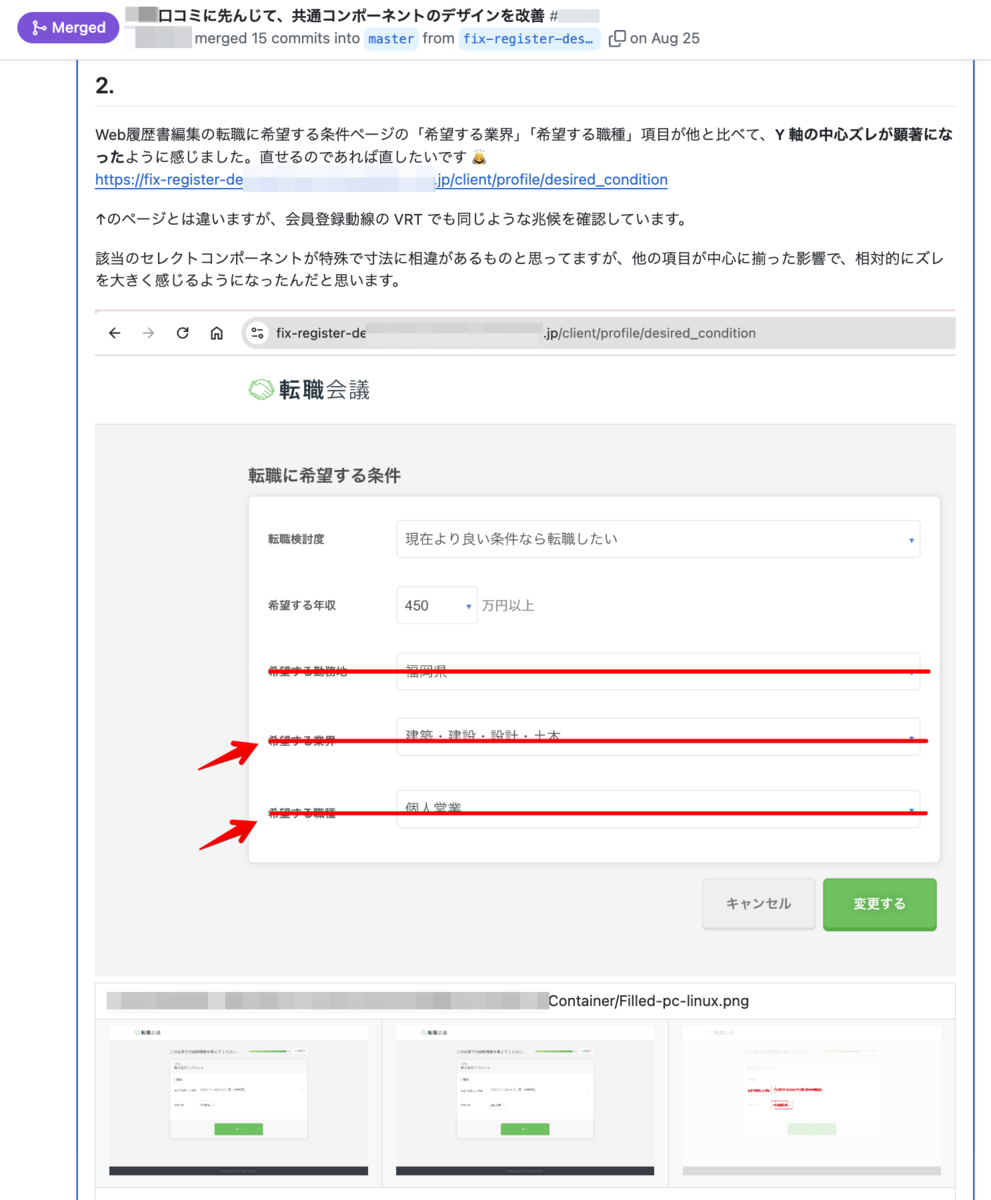
その面倒を AI によって補おうと試みたのが VRT の要約です
具体的にはこういうやつです。先ほどの例のように、見出しの途中で折り返してしまうビジュアル変化を理解して自然言語で説明してくれます。

別の検知例では、スクショに映り込んだ ラベルの表記ゆれの指摘 で修正に至ったこともあります。ゆれが起きているのが Pull Request のコード差分の範囲外だったため、通常のコードレビューでは気付きづらい箇所でした。エンジニアの作業漏れだけでなく、企画やデザインレイヤーの指摘までこなすお節介さがうざいというか頼もしいのです。
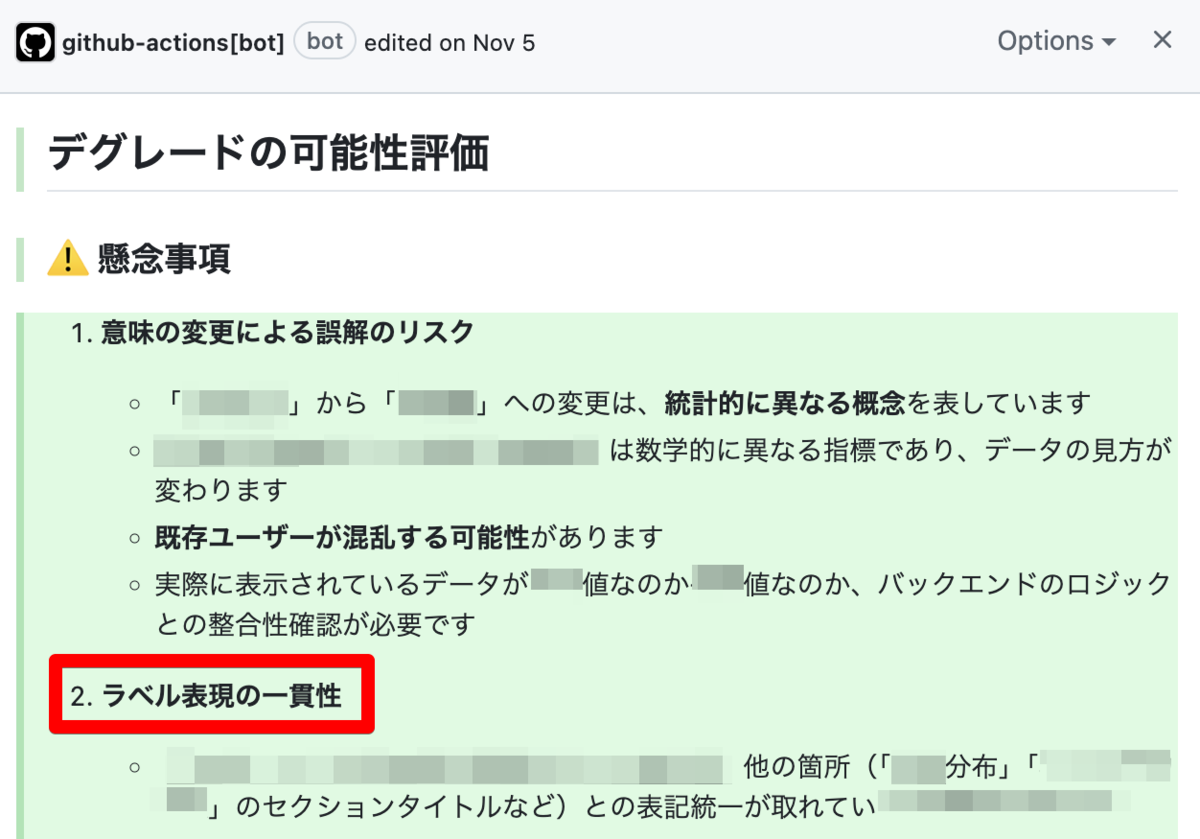
実現するだけなら特別難しいということはありません。AI (LLM) に渡す材料さえ揃えることができれば、比較的容易に導入できます。訓練データがほとんどない数十行のプロンプトでもそれなりの要約を出力してくれることが多いです。
要約生成に使っているツールは Claude Code です。まず PoC として試してみたかったので、簡易的な CLI で実現しています。2025 年に Claude Code が流行り始めた頃、部署内でも試験的に導入されました。コマンドラインからも使えるツールだったので CI とも連携しやすいこともあり、課題となっていた VRT の CI に試しに組み込んでみた。という経緯です。
< prompt.txt claude -p --verboseのストリーム出力 (jsonl) から結果を取得- permission は
/tmp/vrt/**/*に対する読み取り許可のみ - 1 レビューのコストは平均
$0.2~$0.3ほど 要約生成が走るのは VRT の結果で差分が発生したときのみ - モデルは Sonnet 4.5 (2025/12 時点のデフォルト) Haiku 4.5 も試したが、難易度が高いのかシングルプロンプト構成では実用に耐えず
初期に導入したプロンプトは以下のような感じです。※ ブログ向けに微調整しています
## 要件 Visual Regression Test の結果を参考にして、デグレードの可能性を検証してください。 **[重要]** 出力形式は忠実に守ってください。 ## 期待するアウトプット 出力形式: # Visual Regression Test Analysis **{🔥 or 🔴 or 🟡 or 🟢 あなたの結論を 1 行で}** {結論に至る簡潔な説明} ## {Heading 1 e.g. 差分画像のピックアップ} {Content1} 以下の見出しに従い Markdown 形式で出力してください。 1. 差分画像のピックアップ 2. 特記事項 アイコンの選択基準: - 🔥 Critical: マージをブロック、即時修正が必要 - 🔴 Danger: マージ前に対処すべき - 🟡 Notice: マージ後に対処可能 - 🟢 Good: 安全にマージ可能 ### 差分画像のピックアップ 出力形式: ### {選んだ差分画像を表現する見出し 1} {選んだ差分画像の簡単な説明と特記事項 1} <table> {選定基準に従って、変更前後の画像比較テーブル行をコピー&ペーストしてください} </table> VRT 結果コメント (/tmp/vrt/result_comment.md) から変更前後の画像比較テーブル行をコピー&ペーストしてください。以下の選択基準に従って、最小 1 行 〜 最大 2 行のテーブルをコピー&ペーストしてください。 **元のテーブル行の内容を変更せずに維持する必要があります。** 選定基準: - SP (smartphone) レイアウトの差分画像を優先してください - 異なる種類の変更(レイアウト、色、テキスト、コンポーネント等)をそれぞれ 1 つずつ選んでください - ユーザーへの影響が大きい画像を優先してください ### 特記事項 出力形式: | レベル | 説明 | | ------ | -------------------------------------------------------------------------- | | 🔥 | モバイルでログインボタンが消失 - マージ前にレスポンシブ CSS を修正 | | 🔴 | PR タイトルとコメント範囲に一致しない意図しないビジュアル変更 - 影響を確認 | | 🟡 | テキストの色コントラストが低すぎる - テーマカラーを更新 | | 🟡 | ラベルに表記ゆれ - ラベルを更新 | | 🟢 | ◯◯◯ な点で UX/UI が改善しています | 特記事項が見つからない場合は、「特記事項はありません。」と記載してください。 各特記事項についてレベル、説明と推奨アクションを記載してください。 ## Reference 以下のファイルとディレクトリを参照してください。 | Path | Description | | -------------------------- | ---------------------------------------- | | /tmp/vrt/result_comment.md | VRT 結果コメント | | /tmp/vrt/repo | このリポジトリのソースコードディレクトリ | | /tmp/vrt/pr_view.txt | この Pull Request の説明 | | /tmp/vrt/pr_diff.txt | この Pull Request のソース差分 | | /tmp/vrt/modified_images | VRT によって作成された変更前後比較画像 |
渡しているファイルの補足
| ファイルパス | 説明 |
|---|---|
| /tmp/vrt/repo | ビジュアルが崩れた原因をソース全体を見て判断してほしいから |
| /tmp/vrt/result_comment.md | よくある Before, After, Difference の 画像が表示する 3 列テーブルの HTML、ここからコピペして GitHub に貼り付ける用のコメントを作ってもらう |
| /tmp/vrt/modified_images | ↑ の 3 列テーブル内の全ての画像ファイルをコンポーネントのパスと同じツリー構造で格納、これをみてビジュアル変化の内容を認識してもらう |
| /tmp/vrt/pr_view.txt | gh pr view ${pr_number} で取得した Pull Request 情報 |
| /tmp/vrt/pr_diff.txt | gh pr diff ${pr_number} で取得した Pull Request 差分 |
長い前置きは以上でここからが本題になります。LLM 素人の体験談になる関係で文体が崩れることをご了承ください。
VRT の Flaky Test を重大なデグレード扱いする事案がぼっ発
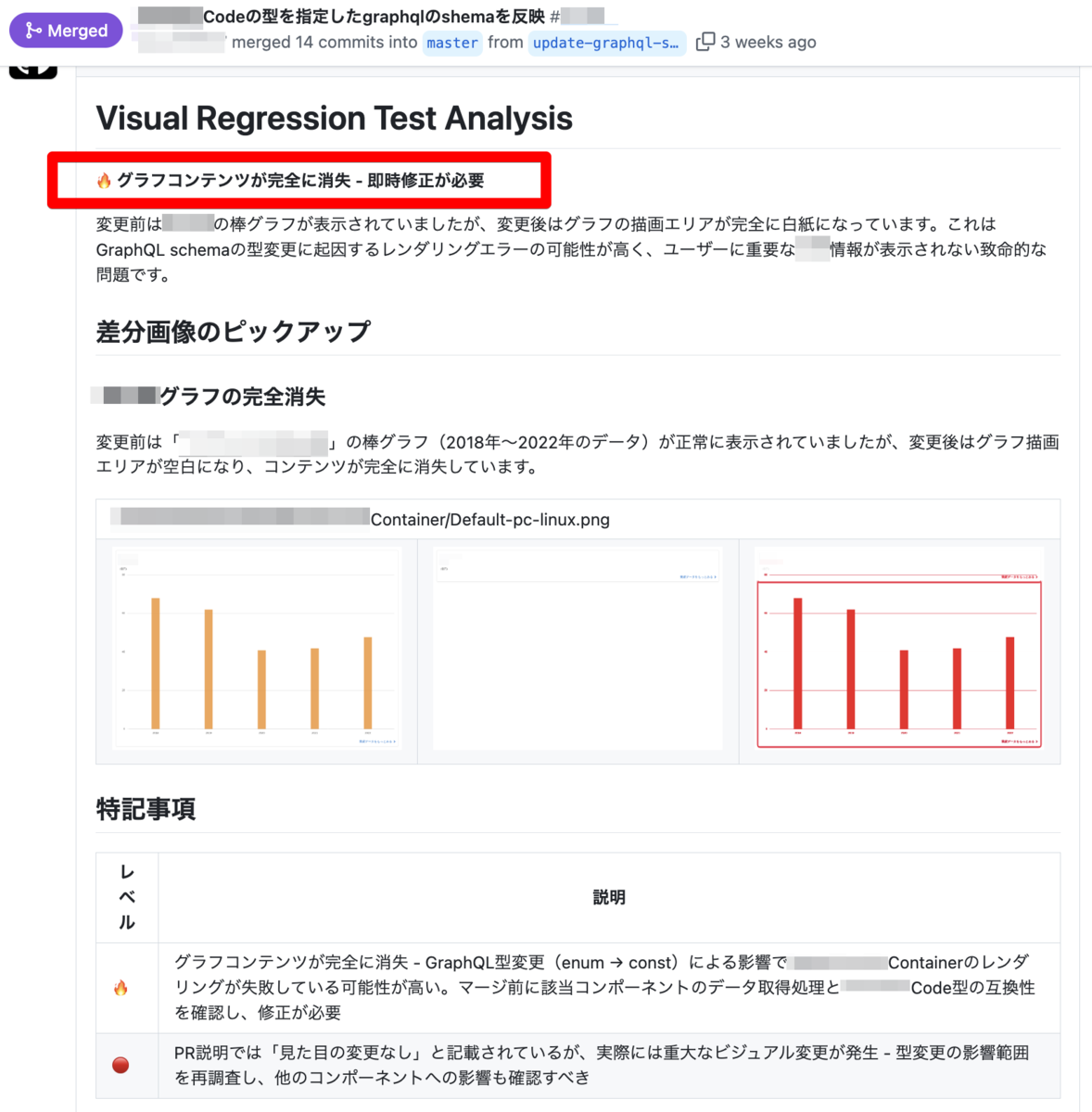
とある TypeScript の型強化 Pull Request で起きた事件である。いつものように VRT のテスト結果を見て、ああまたいつもの画像差分が出たな。CI でレンダリングの最中にスクショを撮影することで起こる、俗にいう Flaky Test である。Playwright の画像比較はこういう遅延系の描写ブレには強い 1 ほうだが、ハズレの CI コンテナを引いたりするとたまに出ちゃうのよね。と思った矢先、問題の VRT 要約が投稿される。


マージすべきではありません。 て。そこまで言わんでも・・。こんな理不尽な罵倒を浴びても、黙って見なかったことにしてくれたレビュイーの新人エンジニアに謝意を込めて、プロンプトの改善を行うことを決意する。
とはいえ、少なくとも人間が Flaky Test と判断できる材料は全て AI に渡してるとは思うんだが、あまり有効活用できていないのか。はたまた、どこかで判断をミスっているのか。まずは AI の思考の過程 を確認して、原因を突き止める必要がありそう。
Chain-of-Thought (CoT / 思考の連鎖) プロンプティング
AIに 結論だけでなく「途中の考え方」を段階的に整理して推論させる 手法です。問題をステップに分けて考えさせることで、複雑な推論や計算の正確性が向上します。特に論理問題・数式・要約・判断理由の明示が必要なタスクで効果を発揮します。by ChatGPT
VRT の要約は Haiku の回答がポンコツ化する程度には複雑な課題だし、要約・判断理由の明示が必要。と言われれば多分まあそんな気がする。どちらにしろ AI の思考の過程をトレースしたり誘導したりするには良さそうなので、さっそく実践してみることにした。
プロンプトのチューニングに関しては右も左もわからない私に、ChatGPT が教えてくれたプロンプトエンジニアリングの教科書的なサイトにも解説があったので見てみる。
https://www.promptingguide.ai/jp/techniques/cot
ゼロショット CoT で AI の思考の連鎖をダンプする
なんかかっこいい。サガフロのウェポンか連携技にこういうのあったような。どうやって使うのかというとプロンプトのどこかに以下を入れれば OK とのこと。
ステップバイステップで考えてみましょう。
これだけで以下のような効果が期待できるという。
- ステップの過程により AI の回答がリファインメントされて、正答率が上がる
- AI の思考過程のどこがおかしいのか、ヒントを得ることができる
先程のプロンプトだとこんな感じに直す。
@@ -1,5 +1,6 @@ ## 要件 +正しい答えを得るために、ステップバイステップで分析の過程を残しながら、 Visual Regression Test の結果を参考にして、デグレードの可能性を検証してください。 **[重要]** 出力形式は忠実に守ってください。 @@ -22,6 +23,7 @@ Visual Regression Test の結果を参考にして、デグレードの可能性 1. 差分画像のピックアップ 2. 特記事項 +3. ステップバイステップの分析過程
5-6 回ほど実行した結果、変更前と比べて 明らかにファイル読み込みの回数が増えている様子を観測する ものの、だいたい以下のようなステップであの誤爆に至っていた。残念ながら、ゼロショット CoT プロンプティングだけでは期待した回答は得られなかったが、AI がどこに囚われてデグレードと判断しているか概ね理解できた。
- Pull Request 情報の読み込み
- VRT 結果と画像読み込み
- ビジュアルの変化からグラフが消失していることを確認
- (ないときもある) 原因分析
- 画像のファイルパスから、撮影対象コンポーネントのリポジトリ上 (/tmp/vrt/repo) のソースファイルを特定
- /tmp/vrt/repo から、撮影対象コンポーネントのソース内容や関連ファイルを走査
- 撮影対象コンポーネント内に
if (xxx) return null;の記述を発見
- (まれに出る) 因果関係分析
- Pull Request のソース差分が、なぜ差分画像のようなビジュアル変化をもたらすのか、リポジトリ上 (/tmp/vrt/repo) のソースを走査
- デグレードリスク評価
- 🔴 重大なデグレードの可能性(高リスク)
提示したファイルはまんべんなく読み込んではいるが、それがうまく結果に繋がっておらず。撮影対象コンポーネントの if (xxx) return null; を見るやいなや、深く考えるのをやめてしまっているケースが多い。
ただ、とある試行で「因果関係分析」というステップが出たことがあり、このときだけは Pull Request による変更はビジュアルの変化と何の因果関係もありません。と非常に惜しいところまで推論ができていた。
フューショット CoT で AI の思考の連鎖を誘導する
そこで、ゼロショット CoT で得た「因果関係分析」ステップを参考に、VRT の結果を Flaky Test と断定するまでの考え方の過程を例示してみた。
@@ -5,6 +5,55 @@ 正しい答えを得るために、ステップバイステップで分析しながら、 Visual Regression Test の結果を参考にして、デグレードの可能性を検証してください。 +## 事前分析 + +以下のステップに従って、事前に情報を整理してください。 +後続のすべてのセクションに情報を提供し、包括的なカバレッジを確保するためです。 + +1. 差分画像分析 +1. リポジトリ分析 +1. 因果関係分析 + +### 差分画像分析 + +各差分画像を読み込んで、情報を抽出してください。 + +1. VRT の結果から全ての画像を読み込む (/tmp/vrt/modified_images) +1. 変更前の画像のキャプションと説明を注意深く読む + - **見出しテキスト** があれば記憶する + - その他の **詳細テキストの要約** も記憶する +1. 変更後の画像や差分から変更の全体像を捉える + - 各画像が示している内容(変更前/変更後の状態)を記憶する + - 変更の種類(レイアウト、色、テキスト、コンポーネント等)を記憶する + - 影響の範囲(ページセクション、コンポーネント、要素)を記憶する + +### リポジトリ分析 + +事前処理: + +1. ソース差分を読み込む (/tmp/vrt/pr_diff.txt) + +以下のステップはソース差分の変更ファイルごとに実行する: + +1. リポジトリソース (/tmp/vrt/repo) を参照して、変更ファイルの内容を理解して要約を記憶する +1. ソース差分のモジュールが使われている上位ファイルも読み込み、理解して要約を記憶する +1. ソース差分の箇所が複数コンポーネントから参照されている場合は **要注意の懸念点** として記憶する + +### 因果関係分析 + +全ての差分画像ごとに以下の手順を実行してください。 + +1. 画像差分のファイルパスとリポジトリソース (/tmp/vrt/repo) を照合する + - 差分が発生しているコンポーネントのファイルパスを特定する + - 特定したファイルを読み込んでブレイクダウンを行い、差分画像分析を元にソースの変更箇所を推測する +1. 実際のソース差分を読み込む (/tmp/vrt/pr_diff.txt) +1. 推測した変更箇所と実際のソース差分を照合して、Pull Request との因果関係率 (0-100 %) を算出する + - 完全一致: 80-100% + - 部分一致: 40-79% + - ほぼ無関係: 10-39% + - 無関係: 0-9% +1. 因果関係率が 15 % 以下の場合は、その画像差分を **Flaky Test** と断定する必要があります + ## 期待するアウトプット 出力形式: @@ -74,6 +123,21 @@ VRT 結果コメント (/tmp/vrt/result_comment.md) から変更前後の画像 - 🟡 Notice: マージ後に対処可能 - 🟢 Good: 安全にマージ可能 +### ステップバイステップの分析過程 + +事前分析の全ステップの分析プロセスを文書化してください。透明性と徹底性を確保するために、各ステップの調査結果、推論、結論について詳細な説明を提供してください。 + +出力形式: + +``` +<details> +<summary>差分画像分析</summary> + +{分析プロセスを詳細に説明してください。} + +</details> +``` + ## Reference 以下のファイルとディレクトリを参照してください。
基本的には、「期待するアウトプット」や素材には手を加えずに「事前分析」という項目を手前に置いただけである。Few-shot CoT を意識はしてみたが、最終的な結論までは例示していないし、若干手続きに寄っている気がするので、狭義の意味で CoT かと言われるとまたちょっと違う気がする。広い意味でのマニュアル型 CoT と言ってもいいのかしら。
先ほどのステップバイステップの分析過程の出力はそのまま残して折りたたんでおき、必要に応じて開けるようにしておいた。また変な要約ができたときはデバッグしやすくしておきたい。
各ステップの詳細はこの記事の本質ではないので内容は省くが、因果関係分析で算出した因果関係率が低いものを Flaky Test と断定させるのが鍵である。因果関係率の算出精度を高めるために私は上下の二軸から攻める戦術を立てる。ビジュアルの変化を起点に上流のレイヤーから下流へ。Pull Request の差分を起点に下流から上流へ。互いのストリームが交差するか否かによって因果関係率を算出を行う考え方、私はこの作戦を「オペレーション天地挟撃」と名付ける。この作業、プログラミングや設計における処理のブレイクダウンに近くてとても楽しい。
Before
After
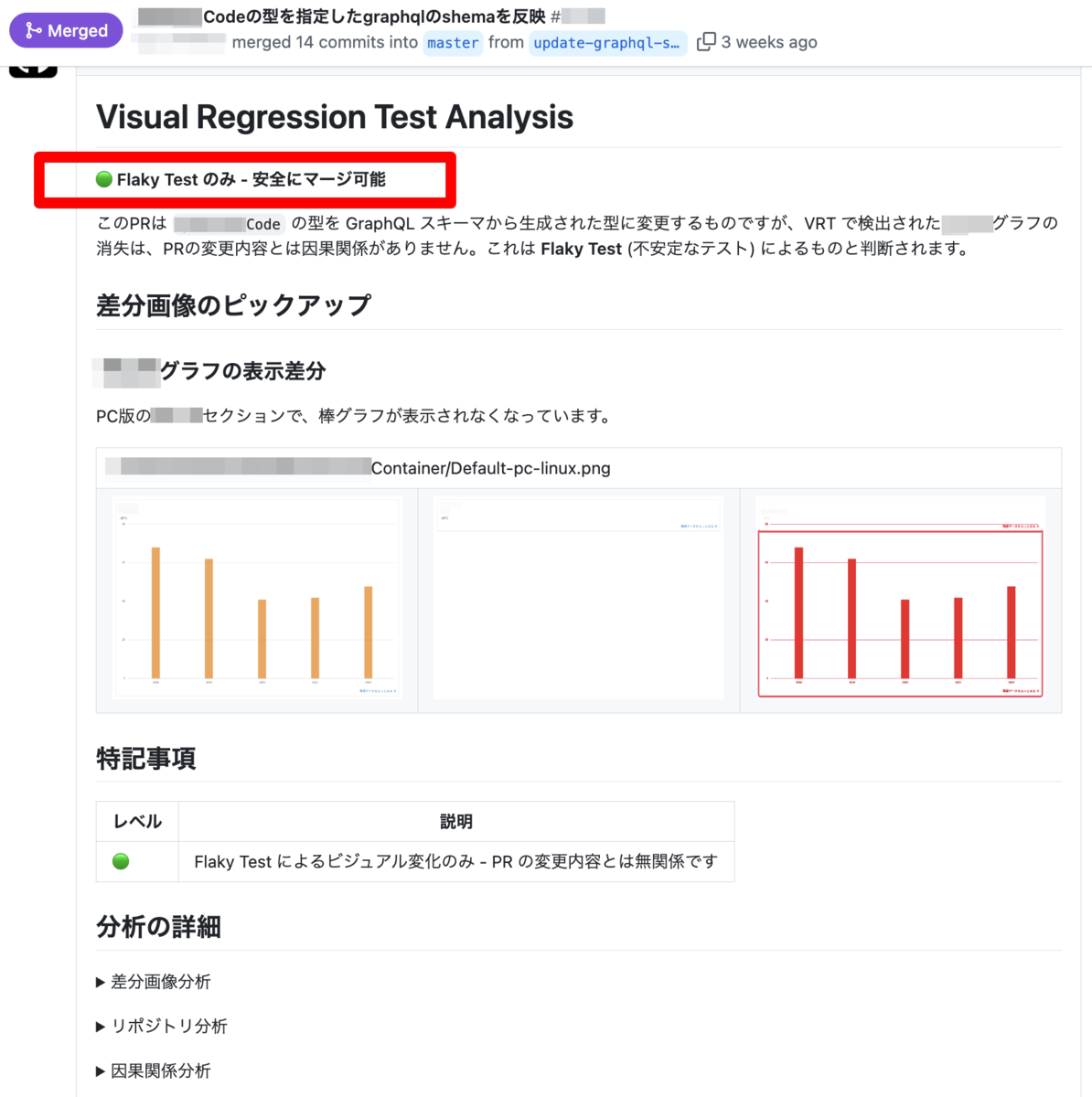
これを待ってた。ただ、完全に安定しているわけではなく 5 回に 1 回はデグレード判定が出ることがあった。これは元の Pull Request が enum 型から literal 型の union に変える差分だったため、挙動に変化が出る可能性が否めないという懸念だった。ある意味そういう見方もあるよね。結果、Pull Request をリリースしても問題なしだったので、Flaky Test 判定が正解いうことになる。
さいごに
推論の過程を考えて自然言語でプログラミングしていく感覚はとても新鮮で楽しかった。ブラックボックスで不安定な回答を安定させる効果も期待できるし、何よりもデバッグしやすくなるのはすごく助かる。
もちろん、CoT は銀の弾丸ではなくデメリットもある。ステップを増えすぎると AI の思考が増える分 input & output tokens も増えて、単純コストがかさむ。
また、他ステップで得た情報で認知バイアスがかかり、判断が歪むケースもあった。例えば、共通コンポーネントをいじって、明らかに Pull Request の説明とは別の場所でビジュアル変化が出ているのに「これはデグレではありません」の一点張り。インタラクティブモードで、なんでやねん。と激詰めしたら、「事前のリポジトリ分析により、このコンポーネントは共通で使われていることは明らかです。Pull Request の意図とは相違がありますが、UI が統一化されることは理想であり、こちらのビジュアルも合わせて変わるべきです」と。あなたの言っていることは正しい。でも、世の中それでは回らないんだよ。
与える情報を制限することも回答の精度を高めるためには大切なことなのかもしれない。極端な例えだが、単純に 1 + 1 = は ? と聞いたときの回答がブレることは考えづらいが、あなたは IWGP タッグ王座のチャンピオンです。と付け加えるだけでまた別の正解が返ってくる可能性が高くなるからだ。
これに対抗する方法の 1 つとして Prompt Chaning 2 というテクニックもあるらしいので、また行き詰まったときに試してみたい。
難しいタスクを簡単なタスクに分解する。 この点が重要なのは普段のエンジニアリングでもプロンプトエンジニアリングでもそう変わらないのかもしれない。
以上、ありがとうございました。
-
toHaveScreenshot
This function will wait until two consecutive page screenshots yield the same result, and then compare the last screenshot with the expectation.https://playwright.dev/docs/api/class-pageassertions#page-assertions-to-have-screenshot-1↩ -
この方法は、LLMが一度に扱うには複雑すぎる詳細なプロンプトに対処する際に有効です。https://www.promptingguide.ai/jp/techniques/prompt_chaining↩