

概要
テクノロジカルマーケティング部インフラストラクチャーグループの春日です。
弊社ではアルバイト求人サイトの マッハバイト を運用しており、2023年9月現在オンプレからAWSへの移行が進んでいます。
上記移行プロジェクトの一環として、マッハバイトの求人画像ファイルが保存されているオンプレNFSサーバーのデータをAWS S3 Bucketに移行しました。 やり方としてはオンプレNFSサーバー側とAWS S3 Bucket側との間でファイルを同期する仕組みを事前に構築し、無停止でマイグレーションしました。
うまくいった点やいかなかった点があり、やったことを本記事で振り返りたいと思います。
オンプレNFSサーバー
弊社では長らくオンプレのデータセンターでNFSサーバーを運用し、各種画像ファイルなどを管理していました。 2023年9月現在はマッハバイト以外の弊社サービスはクラウド移行が完了しており、オンプレNFSサーバーに依存しているのはマッハバイトだけでした。
マッハバイトの求人画像ファイル数は1600万以上あり、容量は1TB程度です。 そこまで大規模ではないですが、小規模と言えるほど少なくはないデータ量ではないでしょうか。
なお、正確にはNFSサーバーは冗長化のためファイルを触るクライアントのサーバー上で稼動しており、実体の GlusterFS サーバーは別にあります。 本記事の都合上、このGlusterFSサーバーのことをNFSサーバーと呼称します。
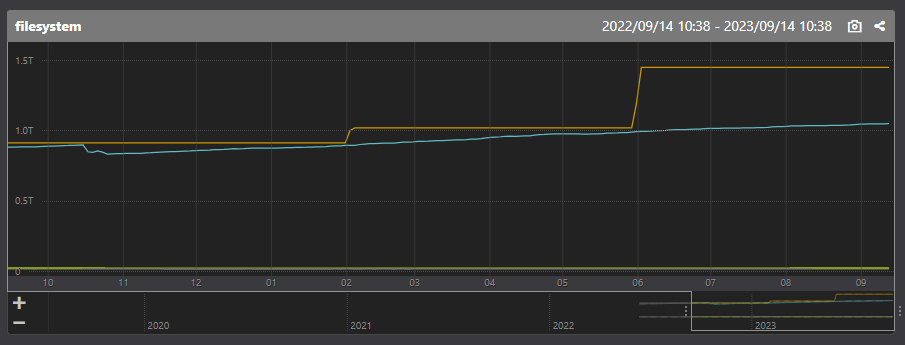
NFSサーバーはシャーディングはせずにシンプルなレプリケーション構成を取っていました。 しかしNFSサーバーのデータは肥大化する一方で、アラートが鳴る度に容量を増設してきました。
以下の Mackerel のグラフでオレンジ線が最大容量、水色線が実際のデータ量の推移を表しています。
移行対象アプリケーション
2023年9月現在、マッハバイトはクラウド移行の過渡期です。 弊社のオンプレデータセンターとマッハバイトのAWS VPCとはAWS Transit GatewayでVPN接続されています。
AWS移行過渡期という事情で、画像ファイルを触るアプリケーションはAWSとオンプレに点在し、画像ファイルはオンプレのNFSサーバーに保存されている状況です。
ファイルを操作する必要のあるアプリケーションのうちクラウドに移行済みのものはAWS ECS on EC2構成を取っており、Container Instance上でオンプレNFSサーバーをマウントし、コンテナ上でホストのディレクトリをボリュームマウントして使っています。
ファイル操作の発生するアプリケーションは以下の3つです。これらの参照先をオンプレNFSサーバーからAWS S3 Bucketへ移行する必要がありました。
- 画像変換サービス
- 求人画像を表示する際にサムネイル表示用にサイズなどを変換して出力する内製サービスです
- httpで元画像データにアクセスでき、オンプレNFSサーバー上のNginx経由で画像を参照しています
- S3 APIを用いてAWS S3 Bucketにアクセスする機能もあります
- 2023年9月現在はオンプレのデータセンターで動いています
- 企業管理画面
- マッハバイトで求人を掲載する企業や店舗の採用担当者様が使う管理画面です
- 求人原稿を管理する機能があり、そこでファイルの更新が発生します
- AWS ECS on EC2上で動いています
- 社内管理画面
- マッハバイトを運用している弊社スタッフが各種データを管理するための社内ツールです
- 創業時から存在するPHPで書かれた古いアプリケーションです
- 求人画像を一括で更新する機能でファイル操作が発生します
- AWS ECS on EC2上で動いています
また、今回はアプリケーション側がファイルシステムへ依存した実装のまま移行するため、S3マウントツールには goofys を利用しています。
無停止マイグレーションの選択と段取り
オンプレNFSサーバーのデータ量は1TB程度で、並列処理してネットワーク帯域を消費すれば4, 5時間程度のタイムアタックでAWS S3側とフル同期が取れます。 しかし4, 5時間のメンテナンスウィンドウを設けるのはユーザー影響が大き過ぎます。 リリース時の手順の複雑性や障害発生時の切り戻し難易度が高く、あまり望ましいやり方ではありませんでした。
そこでビッグバンリリースにならないようにリリースの影響範囲を適度な粒度に分割して無停止マイグレーションを実現できるようにする手法を選択しました。
まず、オンプレNFSサーバーからAWS S3 Bucketへ、AWS S3 BucketからオンプレNFSサーバーへ、どちらからの更新も反映できるようにした双方向リアルタイム同期の仕組みを構築することにしました。 その仕組みの詳細は次の節で解説します。
双方向リアルタイム同期の仕組みを構築した場合に、その不具合リスクや構築工数がデメリットです。 しかし、それを上回るメリットとして以下が見込めると判断しました。
- ユーザーがサービス内部の変更を意識せずに利用を継続できる
- リリース時の手動によるオペレーション負荷を軽減できる、手数を減らせる
- リリース時の安全性を向上できる、切り戻し難易度を下げられる
実際の移行の段取りですが、まずは比較的アクセスの少ない社内管理画面を先にリリースし、次に画像変換サービスと企業管理画面をリリースする形を取りました。 双方向リアルタイム同期処理を自前構築しているので、想定外のエラーを社内管理画面を犠牲に洗い出しておきたかった意図があります。 また、企業管理画面の求人原稿管理機能では編集した原稿をプレビューできる機能があり、それが画像変換サービスに依存していました。 なので2回のリリースに分けました。
AWS EC2 on ECS構成のアプリケーションはTerraformをapplyした後にContainer Instanceをdrainして入れ替える形でリリースし、 オンプレVMで動いているアプリケーションはAnsible playbookを流す形でリリースしました。 もちろん、デプロイ時に各アプリケーション側でリクエストの取りこぼしが発生しないように諸々設定しておく必要があります。
無停止マイグレーションではありますが、念のため比較的アクセス量が減る日中のお昼休みの時間帯にリリースしました。 休日や深夜作業でもないため、障害が発生してもすぐ止血できる気力と体力、チームのサポート体制があって良かったです。
双方向リアルタイム同期処理の自前実装
この節ではオンプレNFSサーバーとAWS S3 Bucketとの間で、どちらからの更新も検知できるようにした双方向リアルタイム同期の仕組みについて話します。 自前で構築した背景や設計、および考慮しなければならなかった点や失敗・苦労した点などを説明します。
背景: AWS DataSyncの利用を断念
ディレクトリやファイル数が多過ぎてメタデータが肥大化しているせいか AWS DataSync は期待通りに動作してくれませんでした。
そもそも ls コマンドでソートしないオプションを指定しても、なかなか結果が返って来ませんでした。ディレクトリ構造とファイルの分散配置に難がある状態でした。
そこで止むを得ず双方向リアルタイム同期処理を自前で構築しました。
設計: 同期処理の構成要素と実装
同期処理の全体像は以下です。
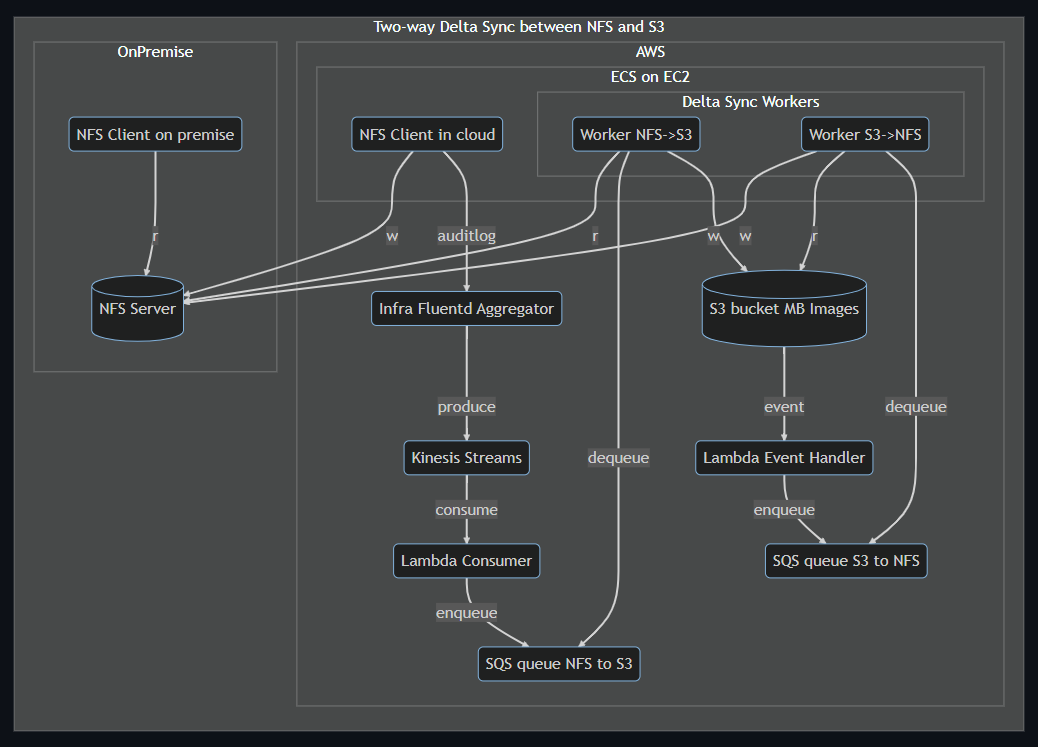
NFSからS3方向への同期は audit log を元に処理します。 S3からNFS方向への同期は S3イベント通知 を元に処理します。 双方向リアルタイム同期処理で利用したツールやサービスは以下です。
- go-audit
- オンプレNFSサーバー側のファイル操作ログはaudit logとして検知できるようにしました
- その生ログのままだと1つのファイル操作が複数行に別れていて扱いにくかったので、まとめて1行のJSONレコードとして出力してくれるこのgo-auditが便利でした
- なおaudit logではマルチバイト文字列は16進数エンコードされているので注意が必要です
- fluentbit
- ファイル操作の発生するアプリケーションが動いているECS on EC2のContainer Instance上でaudit logを拾うために使いました
- メモリバッファの1秒フラッシュ設定で使いました
- fluentd
- 各アプリケーションから転送されるaudit logを受け、AWS Kinesis Streamsに投げるfluentd aggregatorとして使いました
- fluentd aggregator上では特にログレコードの加工処理は行ってません
- AWS Kinesis Streams
- fluentd aggregatorからputされたaudit logのJSONレコードを元に、Lambdaで処理し易い形に整形してからキューイングします
- AWS Lambda
- AWS Kinesis Streamsのconsumerとして発火します
- AWS S3 Bucketの更新イベントで発火します
- どちらも扱い易いようにデータを整形してAWS SQSへenqueueするのが責務の関数を実装しました
- 余計なキューイングがされないよう、同期対象のフィルタリングもここで行っています
- AWS SQS
- オンプレ側のaudit logやAWS S3側のイベント情報を元に同期しなければならないファイルの「パス」と「アクション」情報をキューイングします
- FIFOキューを使いました
- AWS ECS on EC2
- 実際のファイル同期処理を行うキューイングworkerが動作する場所としても利用しました
- オンプレNFSサーバーをマウントしなければならないのでFargateは使えませんでした
- AWS SQSのキューから同期するためのファイル情報をdequeueして同期処理します
Lambda関数やECSタスクのキューイングworkerはGoで実装し、GitHub ActionsでCIできるようにしました。 移行における使い捨てのコードではありますが、頻繁に不具合修正が発生したため同期処理のリリースを自動化しておいたことには大きな意味がありました。
初回のフル同期と同期漏れの確認
初回のフル同期実行では AWS CLI Command を使用しました。 aws s3 syncコマンドでdryrunオプションを指定すると同期漏れリストが取得できます。
今回の移行作業では事故防止のため、なるべく手動オペレーションは避けて進めました。 フル同期や同期漏れ確認作業はBashスクリプトとしてコンテナ化し、CloudWatch Scheduled Eventを設定してECSタスクとして走らせました。
最初、素朴に root ディレクトリを指定して走らせたところ3週間以上かかりそうだったので、そのやり方は断念しました。 対象ファイル数がなるべく均等になるようサブディレクトリをクループ化して11並列で走らせたところ、2日程度かかりました。
1つのECSタスクへのリソース割り当てはvCPU 0.5、メモリ1GB程度で済みました。メモリ512MBだと稀にOOMが発生しました。
循環更新の防止
双方向の同期処理なので循環更新にならないよう気を付ける必要がありました。
NFSからS3方向への同期
ファイル操作の発生するアプリケーション側 (NFSクライアント側) にaudit logを仕込んでいます。 リアルタイム同期workerには仕込んでいないため、workerからの更新は無視されます。
S3からNFS方向への同期
S3 Bucketを更新したのが誰なのか、の情報を元にリアルタイム同期キューイングworkerやフル同期タスクからの更新を無視するようLambda Functionを実装しました。 具体的にはS3イベント情報の中にPrincipal IDがあるので、リアルタイム同期キューイングworkerやフル同期タスクのIAM Roleと一致したら無視するようにしました。
- https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements_principal.html#principal-roles
- https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_identifiers.html#identifiers-unique-ids
このIDはAWS内部で生成される一意なもので、名前のtake overによる権限乗っ取りなどを防ぐためのものです。 IAM RoleやUserを作り直すと変わってしまいます。
最初、このPrincipal IDにはIAM Roleの名前が含まれていると勘違いして循環更新してしまう不具合を出してしまいました。
ファイル操作順序の一貫性と削除操作のリスク
構築した双方向リアルタイム同期処理は様々なツールやサービスを組み合わせて動いています。
最初、同期遅延を減らそうと各所で並列化設定していましたが、実際に発生したファイル操作の順序がバラバラになってしまう不具合が生じました。 作成や更新は冪等ですが削除は危険です。
Kinesis Streamのshard sizeは1に、Lambda発火の並列度も1にして凌ぎました。 https://docs.aws.amazon.com/lambda/latest/dg/lambda-concurrency.html
Lambda関数の責務は軽いデータ加工とSQSキューへのenqueueのみなので並列度を上げなくても、結果的に処理の詰まりは発生しませんでした。 平均して10秒以内に同期は完了します。
一部のアプリケーションではファイルを一括で洗い替え更新する機能があります。 なので削除の後にすぐ作成するパターンが発生します。
万が一順番が逆になってしまった場合に備えて、リアルタイム同期workerの処理内で削除前にファイルの存在チェックを行い、 ファイルが存在していたら削除操作の同期をスキップするように実装しました。
しばらくこのバグに気付けずに flaky な同期差分を出し続けてしまいました。
S3 Bucket更新イベントはフォルダの粒度でも発生する
最初、これに気付かずにファイルのパス (オブジェクトのキー) が来る前提でリアルタイム同期workerを実装したところ、 本来であればディレクトリを作成しなければならない所でファイルを生成してしまうバグを出してしまいました。
同期漏れは手動でリカバリ
aws s3 sync --dryrun コマンドを利用して毎週土日に同期漏れをチェックしました。
数十万件更新あったうちの数百件程度の確率で毎週同期漏れが出ていました。 まったく同期処理で検知できていなかったり、同期処理で拾えてもサイズが違ったりしました。
十中八九、自前構築した同期処理の不具合、もしくは各種コンポーネントの設定チューニング不足に因るものと推測されます。
同期漏れはゼロなのが理想ですが、そこの調査や改善に工数を掛けるメリットも薄いため泥臭い手動リカバリで対応しました。
CloudWatch Logs InsightsからCSVファイルでログを出力し、BashやRubyやスプレッドシートを駆使して対象をリストアップして修正しました。 移行途中のマルチマスター状態の手動リカバリは、どちら側のファイルを正とするかの確証を得てからでないと修正できなかったため骨が折れました。
今思い返すと何らかのデータベースに同期処理結果を保存しておけば、もしかしたら取り回しが良くなっていたのかもしれません。
移行後
今のところ特に大きな障害は発生していません。goofysのパフォーマンスも期待通りで有り難いです。
また、予想外な影響として画像変換サービスのパフォーマンスが向上した点が挙げられます。
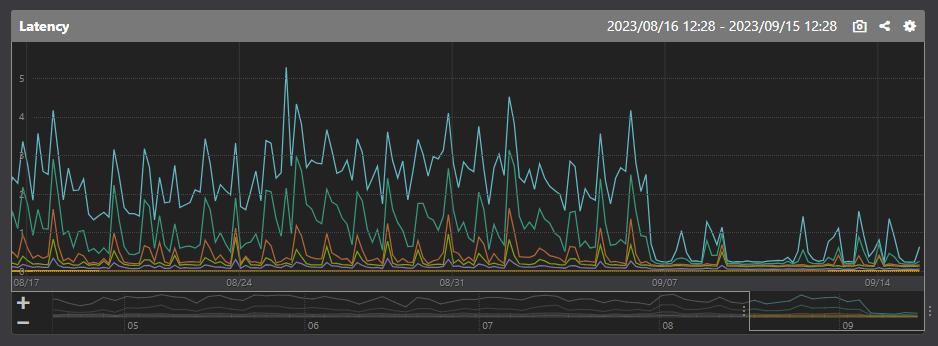
2023年9月現在、画像変換サービスはオンプレで稼動中です。 今まではデータセンターのネットワーク内で完結してオリジン画像ファイルを参照していましたが、 移行後はインターネット越しにAWS S3 Bucketを参照する形に変わっています。 後者の方が数倍速いというのは驚きでした。
マッハバイトは成功報酬型のビジネスモデルで、求職者が採用されて初めて採用側に課金されます。 その特性上、今回の移行対象アプリケーションは月末月初にアクセス量が増える傾向です。
AWS S3へ移行した後の月末月初も無事乗り越えられました。
ユーザー目線では特に何も変化はない移行でしたが、一番のメリットはストレージ容量不足アラートのトイル対応が撲滅されたことです。 今後はその分をコーディングに当てられるようになりますし、チームのモチベーション低下も防げます。
これから
せっかくS3へ移行できたので、アプリケーション側の実装もファイルシステム依存から脱却していく必要があります。 SDKを用いてS3 APIを叩く形へ変えられれば、ECS Fargateへの移行が可能になります。
また、S3に移行したことによって容量を気にする必要がなくなり、オンプレ時代と比較にならないくらい可用性が高くなりましたが、 無料ではないのでデータライフサイクルをちゃんと管理して無駄なファイルは削除していく必要もあります。
2023年9月現在、マッハバイトはインフラストラクチャーグループ総出でクラウド移行を進めています。 Lift and Shift の Shift がまだ進んでいない箇所も多い状況です。 引き続きマッハバイトを開発しているアルバイト事業部と連携しながら移行と改善を進めていきます。