

はじめに
技術部インフラグループの春日です。
2024年現在、弊社が運営している マッハバイト は一部を除いてオンプレからクラウドへの移行が完了しました。 本記事では移行対象の1つであった Apache Solr に関する総括をします。
今回のプロジェクトでは移行自体を最優先とするため、スコープを以下に定めていました。
- Apache Solrから他の検索エンジンへは乗り換えない
- アプリケーション側の改修は向き先の変更だけに留める
- Apache Solr自体のバージョンUP対応はしない
- 運用負荷を軽減できる形の構成変更を加える
- 移行スピードと移行後の運用コストとの天秤
- 新たに運用しないといけなくなるコンポーネントはなるべく増やさない
- モニタリングや監視の精度はなるべく落とさない
上記を踏まえ、以降の節ではApache Solrのサービス内利用箇所の紹介から始め、 インフラ構成・デプロイ・モニタリングについてそれぞれ移行前と移行後を比較し、 最後に現状の課題と将来的な検討事項をまとめる形で振り返ります。
マッハバイトでのApache Solrの使い方
マッハバイトではApache Solrを求人検索機能やファセットナビゲーションの求人件数表示箇所で利用しています。
求人検索機能では市区町村などの地域や路線の駅、職種や時給・時間帯・フリーワードなどの様々な条件を指定できます。

ファセットナビゲーションの求人件数表示箇所では、リンクごとに該当する求人件数を ファセット検索 して表示しています。

なお、元々は全文検索機能でMySQLの Mroonga が使われていましたが、過去にマッハバイトのコードをPHPからRubyへ移植する過程でApache Solrが導入されました。
Index sizeは小さめでシンプルなreplication構成
マッハバイトではApache Solrを純粋に検索用途に特化して使っています。 基本的にIndexing dataは求人IDのみstoreしており、求人の詳細データは検索結果の求人IDを指定して別のデータストアから取得して表示しています。
2024年現在のIndex sizeは数百MB程度と小さいため、shardingはしておらずシンプルなreplication構成を取っています。
求人データのindexingはdataimport機能を使用
Apache Solrには dataimport 機能があり、XMLファイルにSQLを記述することによりApache Solrから直接RDBMSを参照してindexingできます。
外からcURLで叩いてキックできる手軽さもあり、マッハバイトは長らくその機能を使用しています。
コア設定をgitでバージョン管理
Apache Solrにはコアと呼ばれるNamespaceのような概念があり、1つのSolrインスタンスで複数のコアを扱うことができます。
Apache Solrのコア設定ファイルは、日々の開発や運用で変更が発生します。 例えば検索軸が増えた場合にフィールド設定を追加する、キャッシュ設定を見直す、などです。
そのためコア設定のみ専用のgitリポジトリでバージョン管理しています。 Bootstrapping, Configuration, Orchestrationで言う所のOrchestration工程の関連ファイルも含まれています。
内製Pluginで検索結果の出力を調整
Apache SolrのPlugin機能 を用いて出力結果を調整しています。 マッハバイトのアプリケーション側では処理しにくい要件を実現するために利用しています。
構成
冒頭のプロジェクトスコープで述べた通り、今回のクラウド移行ではApache Solr自体を別の検索ミドルウェアに置き換えることはしませんでした。 マッハバイトをクラウドで動かすことを最優先とし、各種最適化は移行してから考えることにしました。
ただ、そっくりそのままクラウドに持って行くのは運用負荷が高いため、ある程度の構成変更はしています。 以下の節では移行前と移行後の構成の違いを説明します。
端的に言うと移行前と移行後でreplication構成なのは変わりません。唯一違う点はfailover設定の有無です。 移行前はfailover可能な構成でしたが、移行後はコンテナ化されて自動復旧し易くなったためIndexer StandbyやSearcherがIndexerに昇格することはなくなりました。
移行前: オンプレVM
移行前の構成は以下です。それぞれのインスタンスはオンプレVM上で稼動していました。
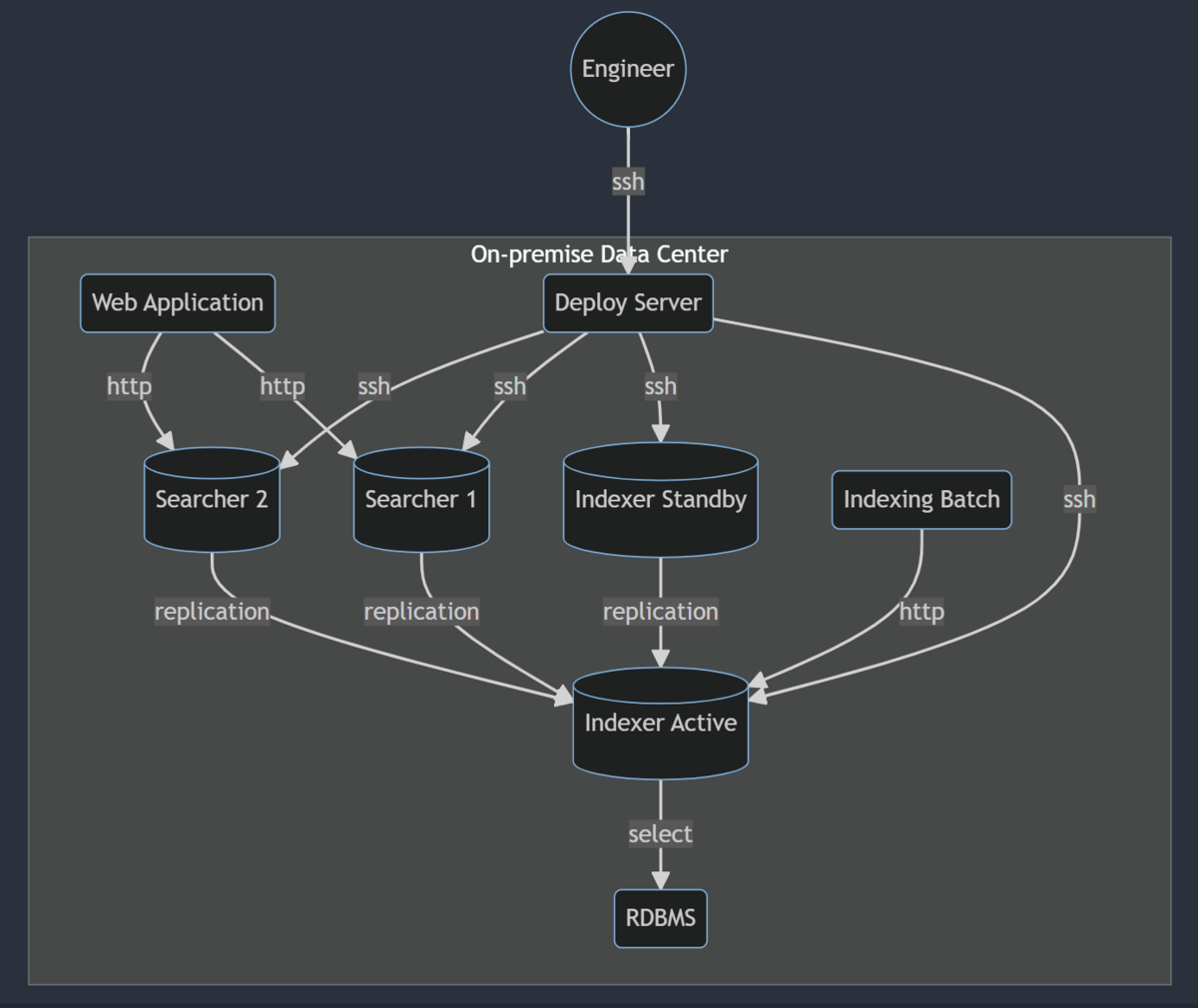
Keepalivedで冗長化
上の図ではL4LBとして Keepalived の存在を省略しています。 実際には各接点の間に存在してロードバランシングしていました。
IndexerはActive/Standby構成
Indexerは万が一に備えてActive/Standby構成にしていました。 幸いにもfailoverが発生したことは今まで一度もありませんでした。
移行後: AWS ECS Fargate, EFS
移行後の構成は以下です。
マッハバイトではクラウド移行でAWS ECSを全面的に利用しています。
ステートフルではありますが、Apache SolrもHTTPで会話するWebアプリケーションです。
index dataの扱いに気を付ける必要がありますが、Apache Solrも他に合わせてECS構成を踏襲しました。
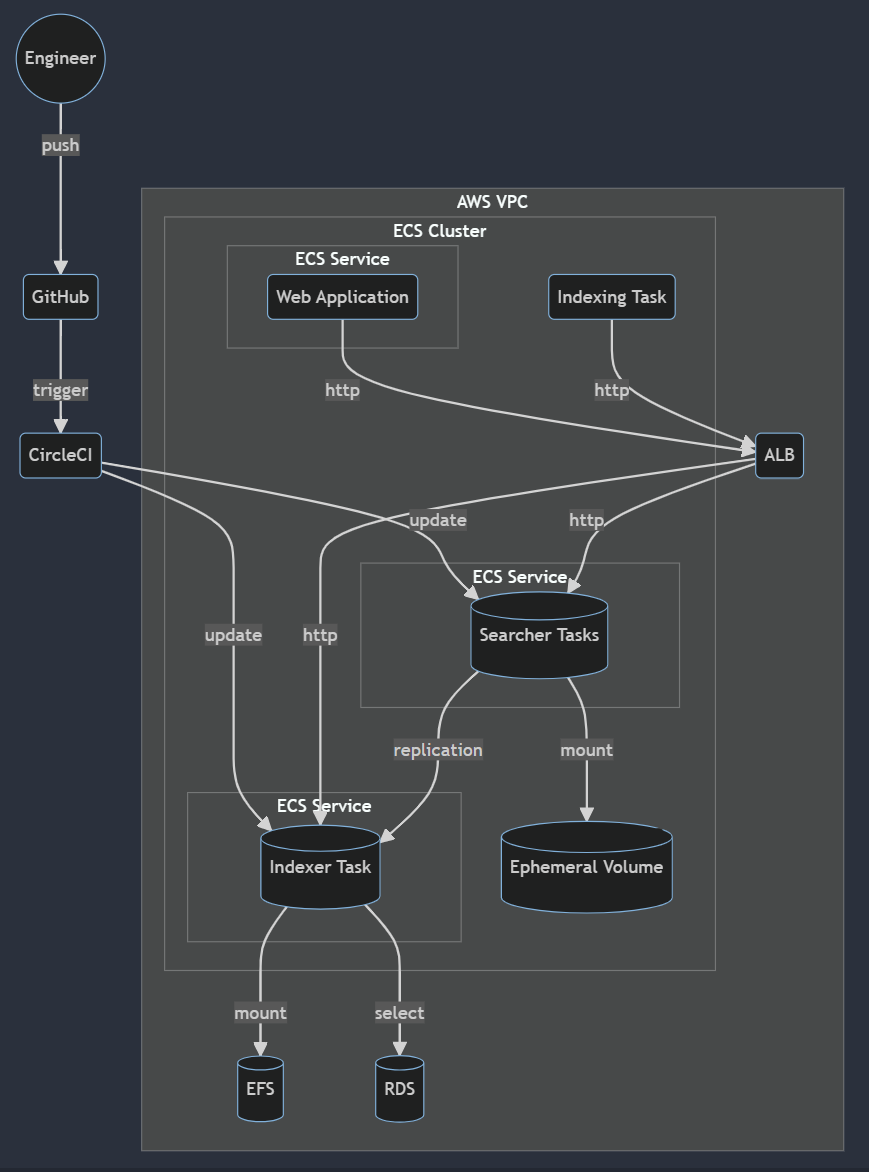
コンテナ化してECS Fargate上で動かす
運用コストを考慮してEC2インスタンスへの移行は選択肢から外し、 コンテナ化してIndexerもSearcherもIndexing Batchも全てECS Fargateで動かす構成を選択しました。
コンテナイメージのビルドには 公式Apache Solrイメージ を利用しています。 それをベースに内製Pluginを追加し、環境変数でIndexerとSearcherの役割を切り替えられるように共通イメージをビルドしています。
Indexerはauto scalingせず、逆にSearcherはauto scalingさせるためECS ServiceはIndexerとSearcherとで分けました。
また、Indexing BatchはECS run taskでCloudWatch Scheduled Eventにて定期実行するよう設定しました。 Apache Solrのdataimport機能をキックするだけで良いのでIndexing Batchは cURL コンテナイメージを利用しています。
IndexerはEFS、SearcherはEphemeral Volumeをmount
フルindexingには30分以上かかります。コンテナの再起動でindexing dataが飛んでしまわないよう、IndexerはEFSでindexing dataを永続化しています。
対してSearcherはauto scalingを考慮してephemeral volumeをmountしています。 ephemeralなのでコンテナの再起動で消えてしまいます。 抽象書き込みレイヤーのオーバーヘッドを回避するため、基本的にデータ領域はボリュームマウントした方が良さそうです。
前提として、index sizeが小さいためSearcherコンテナ起動時の初回replicationにおけるオーバーヘッドが小さい、という条件が挙げられます。
なお、本当はSearcherのvolumeにtmpfsを使ってみたかったのですが、Fargateだと厳しそうだったため断念しました。
IndexerとSearcherとの間にALBがあるとreplicationが切れてしまう
最初replication通信でSearcherからIndexerへの参照にALBを介していたところ、度々replicationが切れてしまう問題が発生しました。
CloudMapのServiceDiscoveryを設定し、replication通信ではIndexerを直接参照するように変更して解消しました。
JVMとコンテナとの相性
比較的新しいJVMは自身がコンテナ環境で動いていることを認識できます。 逆に認識できないと正確なリソース情報が得られず、GCなどが暴走する危険性があるとのことです。
cgroups V2はJDK 17以降でしか対応していないみたいです。
2024年現在のマッハバイトが使っているApache SolrのJDKバージョンとECS Fargateのcgroupsバージョンを確認したところ問題ありませんでした。 が、今後のバージョンUP対応で罠になる可能性があります。ECS FargateのPlatform versionは明示的に指定しておいた方が良さそうです。
デプロイ
先に述べた通りApache Solrのコア設定ファイルをgitでバージョン管理しています。 クラウド移行の構成変更と共に、そのデプロイ方法も変えました。
マッハバイトのWebアプリケーションは各種CIサービスを利用してデプロイされており、 Apache Solrも同様のフローでリリースできた方がデプロイ手順の学習コストが低くなります。
移行前: Ansible, Capistrano
移行前の初期構築では Ansible を使用して各VMにApache Solr本体をインストールしていました。
また、コア設定の変更をリリースするエンジニアがデプロイ用のオンプレサーバーにSSHで入り、 Capistrano のコマンドを叩いてSSH経由でコアをデプロイして再起動していました。
Keepalivedからの安全な切り離しを実現するため、内製の IPVS セッションモニターツールを使用してリクエストの取り零しが発生しないように再起動させていました。
手順書が存在して手数も多く、CIサービスを利用している他のWebアプリケーションと比べると独特で手間を感じることもありました。
移行後: CircleCI
移行後は CircleCI でコンテナイメージをビルドしてECRへプッシュし、ECSサービスを更新する形に変わりました。 workflowでは以下の orb を利用しています。
- https://circleci.com/developer/orbs/orb/circleci/aws-ecr
- https://circleci.com/developer/orbs/orb/circleci/aws-ecs
リリース前の動作確認に使うステージング環境へはgitのmainブランチへのpushで、本番環境へはgitのtagリリースをトリガーにジョブが走るように設定しています。
SSHでサーバーに入って手でコマンドを叩く運用が廃止され、リリース時の心理的負荷も下がりました。
モニタリング
移行前と移行後とでモニタリングツールも変わりました。 マッハバイトのクラウド環境モニタリングでは全面的に Datadog を採用しており、Apache Solrもそれに合わせる形になりました。
移行前: Mackerel
移行前のオンプレ環境ではApache Solrが動いているVM上にAgentをインストールする形で Mackerel を利用していました。 Apache Solr用のいくつかの Mackerel Agent Plugins を組み合せてモニタリングしていました。
公式Plugin
Mackerel Agentの Apache Solr用公式Plugin です。 ドキュメント数やキャッシュのヒット率、indexing dataのサイズなどを確認できます。
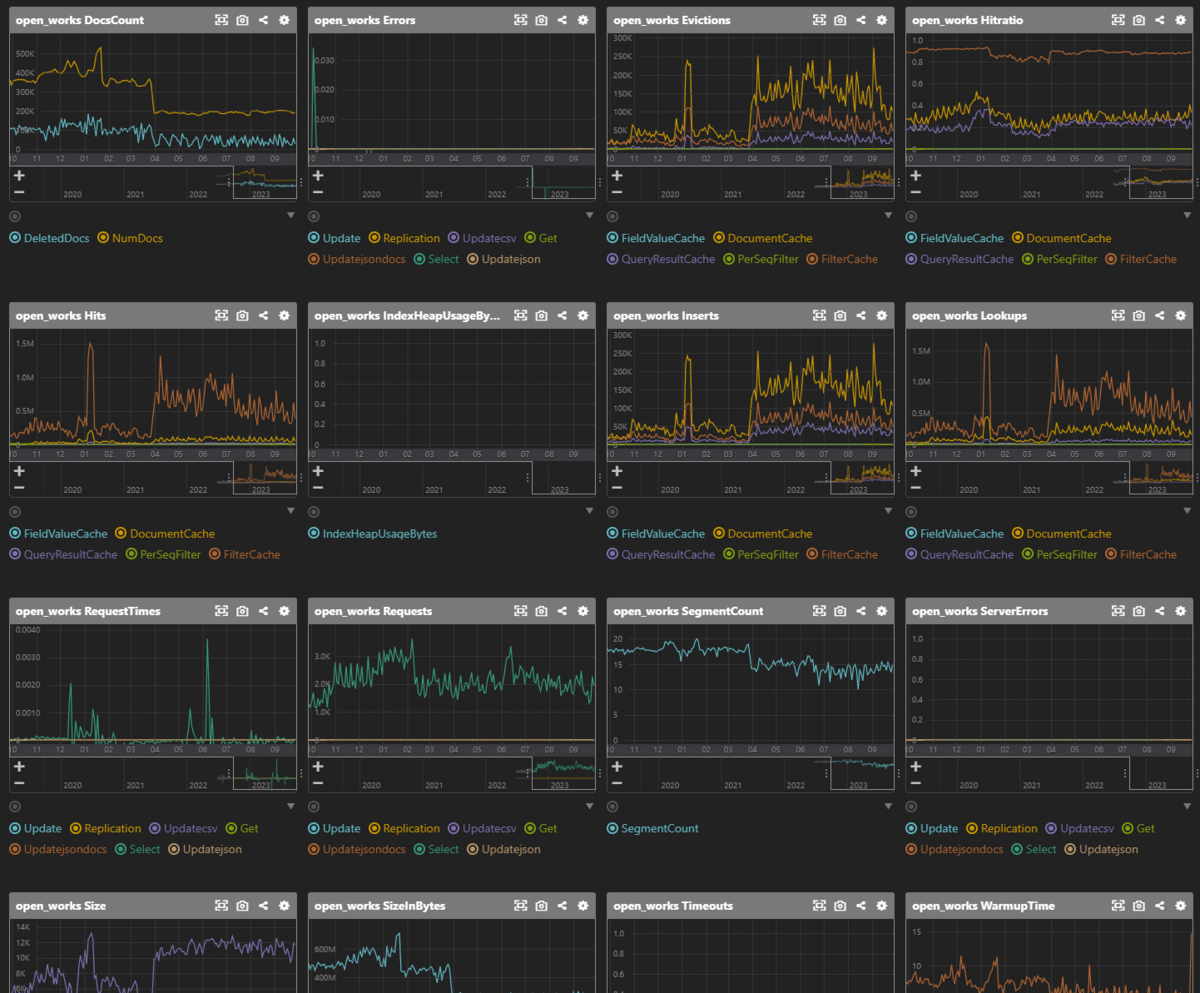
余談ですが最初は存在しなかったため過去に Pull Request しました。 当時はGoを触り出した初期だったので、今になって見返すとリファクタリングしたくなってきます。
その他のPlugin (JVM, dataimport用)
Mackerelでは mkr コマンドという便利なツールがあり、独自のMackerel Agent Pluginsを公開して簡単にインストールできます。
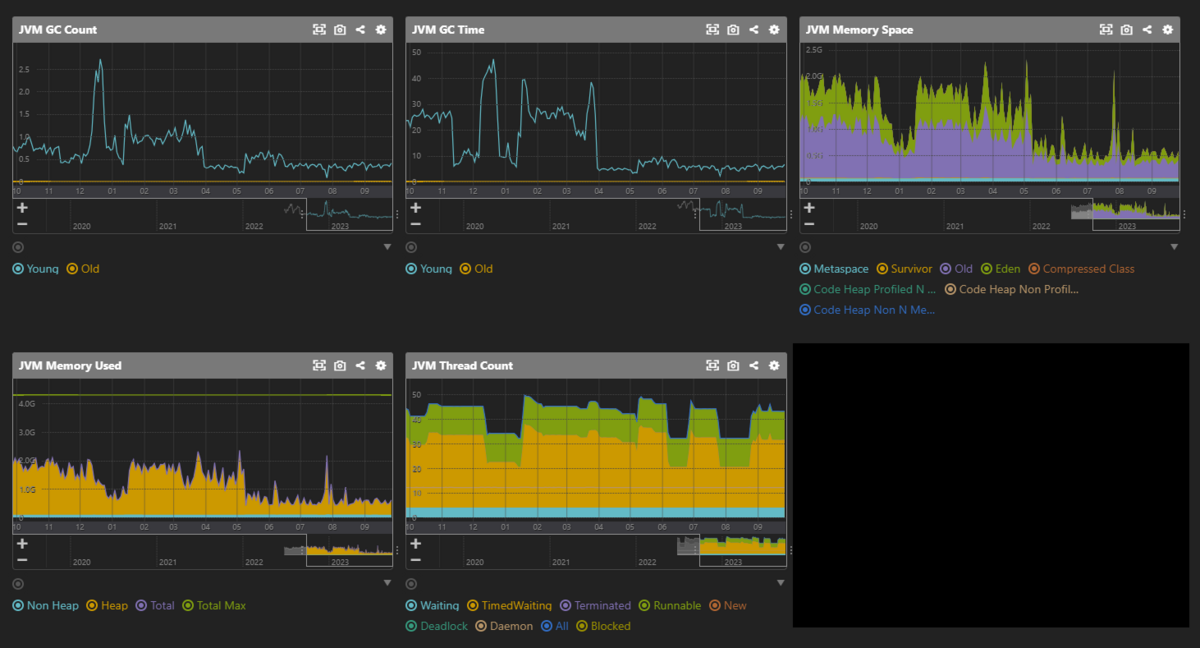
公式PluginはApache Solrの古いAPIを利用しており、JVMに関して追加のモニタリングをするために Apache Solr用JVMモニタリングPlugin を実装して使っていました。
GCのパフォーマンスやヒープ利用量を確認し、JVM関連のチューニングに利用していました。
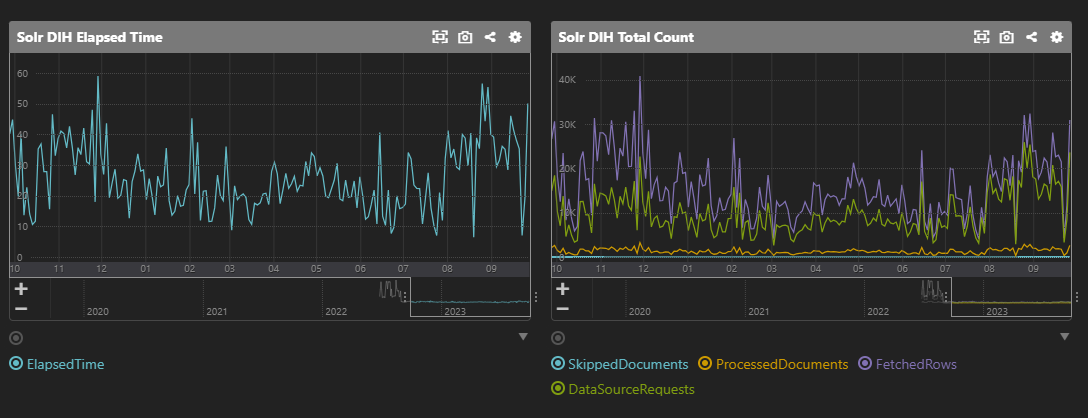
また、Apache Solrの dataimport機能のモニタリング用Plugin も実装して使っていました。
dataimport機能のindexing時間の推移を確認し、パフォーマンス劣化に気付けるようにしていました。
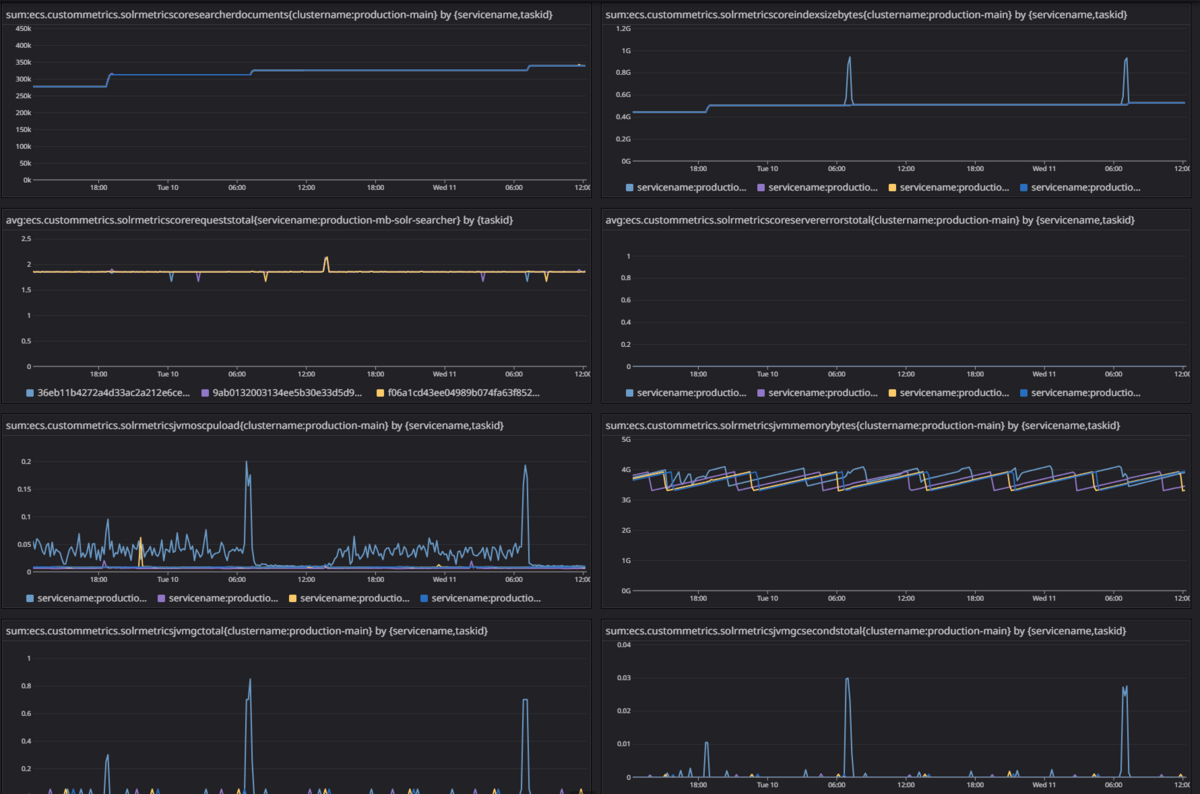
移行後: Apache Solr Exporter, CloudWatch Agent, Datadog Integration
移行後のApache SolrはAWS ECS Fargate上で動いているというのもあり、モニタリングツールも変えました。
Apache Solr Exporter
Apache Solrの各種メトリクスをPrometheus形式で出力してくれる Apache Solr Exporter をsidecarで動かして使っています。 Prometheus形式で出力できるようにしておけば、今後も様々なビジュアライズツール・サービスと連携し易くなります。
Datadog AgentではなくCloudWatch Agentを利用
Datadog Agentだとsidecar構成しか取れず、Searcherのauto scalingを考慮するとDatadogへの課金額が余計に増えてしまう懸念がありました。 KubernetesではDatadog Agentを1つ動かし、対象コンテナ毎のlabel指定でよしなに収集できますが、ECS Fargateだとそのような自動検出機能は使えないみたいでした。
そこでCloudWatch Agentを1つ動かして一度CloudWatchにメトリクスを収集し、DatadogへはIntegration経由で送る構成を選択しました。 なお、CloudWatch AgentもECS Fargate上で動かしていますが、まとまったドキュメントが存在せずに初期構築に苦労しました。
- CloudWatch Agent on ECS で Prometheus メトリクスを CloudWatch Metrics に集約する
- Scraping additional Prometheus sources and importing those metrics
- Detailed guide for autodiscovery on Amazon ECS clusters
- Scraping additional Prometheus sources and importing those metrics
- Manually create or edit the CloudWatch agent configuration file
- Set up and configure Prometheus metrics collection on Amazon EC2 instances
- cwagent-ecs-prometheus-metric-for-awsvpc.yaml
課題
今回のクラウド移行に関係なく、現状のマッハバイトではApache Solrに関して以下の課題を抱えています。 これらの問題はApache Solrを今後も使い続けるか否かの判断にも関わってきそうです。
Indexingのcommitでcacheがpurgeされてしまう
Apache SolrのreplicationはMySQLのbinlogみたいなストリーミング方式ではなく、新旧indexをバツっと切り替えるような挙動をします。 indexが更新されると各種cacheもpurgeされてしまい、そのタイミングでレイテンシーが跳ねてしまう課題がありました。
暖機運転設定 を追加して様子を見ていましたが、アラート頻度は体感的に減ってはいるものの、依然として発生し続けています。 Varnish などを使って防ぐ方法もあるかもしれませんが、運用対象が増えてしまう構成は避けたいところです。
Apache Solr 9からdataimport機能が消えてしまう
もしApache Solrを今後も使い続ける場合は定期的にバージョンUP対応が必要です。
メジャーバージョン9になるとマッハバイトが依存しているdataimport機能が消えてしまいます。 バッチ処理で別のAPIを叩く形のindexing方法に切り替えていく必要があります。
Replicationが不定期に切れてしまい自動復旧しない
Searcherのreplication設定では1分間隔でpollingするようにしています。 しかし何かの拍子にスタック状態に陥ってしまい、何もしないとそのまま同期が停止し続ける事象に遭遇しました。
一度に全てのSearcherが異常な状態になる訳ではなく、ランダムで一部のインスタンスに不定期に発生する傾向にあります。 これはオンプレVM版でもAWS ECS版でも発生しており、ログには何も出力されておらず未だに原因が掴めていません。
今のところネットワーク的な問題か、Indexerへのcommit頻度の問題などが怪しいと考えてますが定かではありません。 issueを検索してもそれっぽい事象は見当らず、バージョンUPで解消するかどうかもわかっていません。
ヘルスチェック用のスクリプトに次回同期予定時刻の値が古過ぎないか否かの判定を加えることで自動リカバリさせるworkaroundで凌いでいます。
# 次回の同期予定時刻が1時間以上前であれば異常と見なす例 next=$(curl -fsSL 'http://127.0.0.1:8983/solr/my_core/replication?command=details&wt=json' \ | jq -r --arg now "$(date -u)" 'if has(".details.slave.nextExecutionAt") then .details.slave.nextExecutionAt else $now end' \ | xargs -I{} date -d {} +%s) dead=$(date -d '-1 hour' +%s) echo "Next: $(date -u -d @$next), Deadline: $(date -u -d @$dead)" test $next -gt $dead
Apache Solr用の内製Pluginのメンテナンス
先述したApache Solrの検索結果出力を調整するための内製Pluginですが、今は誰もメンテナンスができない状態になりつつあります。
今後のApache SolrバージョンUP時に動かなくなってしまう可能性もあります。 Plugin以外の形で要件を実現できないか、今一度再考する余地もありそうです。
今後
今回のApache Solrのクラウド移行は Lift and Shift で言う所の Lift + α と考えています。 なるべく運用負荷を減らす目的でAWS ECS Fargate構成を選択しましたが、今後もこの構成をずっと続けられるとは思っていません。
Apache SolrとSharding
2024年現在、マッハバイトが使っているApache SolrのIndexing dataはsizeが小さいのでshardingする必要がありません。 逆にそのデータ量が肥大化していくと今の構成では耐えられなくなるタイミングが来ます。
Apache Solrでshardingするには、ZooKeeper と組み合せて Solr Cloud を運用する必要性が出てきます。 そこまでの構成となると、AWS ECS Fargate上で動かすのも厳しくなってきそうです。
なお Distributed Search with Index Sharding によるとSolr Cloudを使わない形でもshardingできるみたいですが、 Client側の責務が重そうです。
余談ですが個人的にApache Solrの 標準クエリ はquerystringで表現できて学習コストが低くて気に入ってます。 マッハバイトでは lsolr という独自のGemを利用して検索クエリを生成しています。 Apache Solrのクライアントライブラリとしては rsolr を利用しています。
Elasticsearchの検討
他社様の事例を見るとApache Solrから Elasticsearch への移行がトレンドに見えます。 弊社サービスで検索機能にApache Solrを利用しているのは2024年現在ではマッハバイトのみです。
AWSには Amazon OpenSearch Service が存在します。 運用コストを削減できるのであればマネージドサービスへ移行した方がマッハバイトにとってメリットが大きいと考えています。
Elasticsearchはsharding構成が取り易く、余計なコンポーネントを追加する必要がない点も魅力です。 JSONを駆使した検索クエリの学習コストはかかるものの、運用面や機能面、エンジニア採用面で考えても今後の移行先の選択肢の1つになります。
最後に
インフラグループではマッハバイトのクラウド移行以外にも、過去に社内で共用だったサービスやサーバーも鋭意移行中です。 そのままクラウドに移行しただけでは運用負荷が変わらないため、適宜構成を見直しながら進めています。
引き続き各事業部と連携を取りながらリブセンスのインフラ周りを改善していきます。