
移行の背景
インフラストラクチャーグループの @mom0tomo です。ここ2年ほど、マッハバイトのクラウド移行に取り組んでいます。
リブセンスでは長年データセンターを借りてオンプレミスでサーバーを運用してきました。ただ最近のクラウド化の流れを受け、いくつかのサービス(転職会議や転職ドラフトなど)はオンプレからクラウドへ移行し、また新規事業であるknewやbatonnなどは、初めからクラウドサービスを利用しています。
しかし、創業期からの歴史のあるマッハバイト(旧ジョブセンス)では、ほとんどの本番環境のサーバーがオンプレミスで運用されてきました。
それが昨年、オフィスの移転に伴って社内のサーバールームで運用されていた開発環境のサーバーをAWSに移行したことを契機に、マッハバイトの本番環境でもAWSへの移行が加速しています。
今回は、マッハバイトの中でも最も多くの機能を内包しているモノリシックなアプリケーションをAWS移行した話をします。
どんなアプリケーションを移行したのか
今回移行したのは、マッハバイトを構成するアプリケーションのうちの1つです。
こちらは1つのRailsアプリケーションに複数の機能が入ったモノリシックな構成になっていました。大きく分けると以下の機能です。
- 社内用の管理画面としてのWebアプリケーション
- マッハバイト本体・提携先企業様用の管理画面から呼び出す複数のAPI
- 60を超えるさまざまなバッチ処理
- 毎時実行されるデータ更新処理もあれば、月に一度だけ実行される請求関連の一括処理もある
- 数秒で完了する処理もあれば、何時間もかかる処理もある
このアプリケーションは、移行前にはWebアプリケーション用のサーバー、呼び出しの多い一部API用のサーバー、バッチ専用のサーバーという3種類のサーバーの上にデプロイされていました。
これをAWS ECSに移行し、それぞれの機能ごとにコンテナを分離しました。
なお、バッチについては数が多いため現在も分割して移行作業中です。
移行後の構成
AWS移行にあたって利用したサービス・ツールは下記のとおりです。
- インフラストラクチャー
- AP: AWS ECS(Fargate)
- バッチ処理: AWS EventBridge Scheduler + AWS ECS(Fargate)
- 構成管理
- Terraform
- CI/CD
- GitHub Actions
- モニタリング・監視
- Datadog
- Cronitor

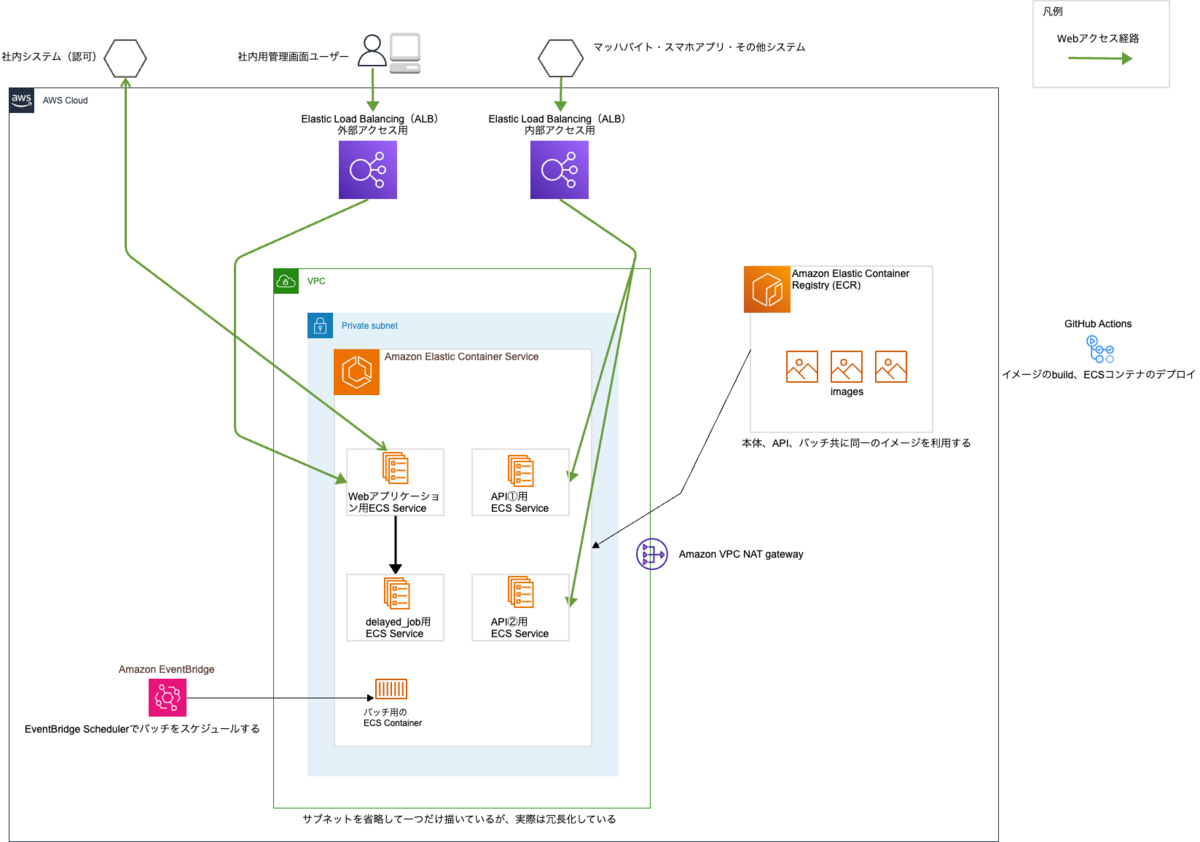
マッハバイトでは、AWS移行後のコンテナオーケストレーションツールとしてECSを採用しています。ECSはEKS等に比べて学習コストが低く、アプリケーションエンジニアにも馴染みやすいところがあるためです。
またバッチ処理については当初はECSとEventBridge Ruleを採用する予定でしたが、2022年11月にリリースされたEventBridge Schedulerがより高機能で便利だったため、EventBride Schedulerを採用しました。
イメージのbuildやリリースなど、CI/CDにはCircleCIが利用されてきましたが、AWS移行にあたってGitHub Actionsを標準として採用するようになりました。GitHub Actionsはインフラグループが先行して採用しており、その使い勝手の良さからマッハバイトに展開したものです。
また構成管理については、オンプレ時代はAnsibleを利用していましたが、AWS環境ではTerraformを利用しています。Terraform自体は今回の移行で導入されたわけではなく、AWSに新規構築するリソースなどは管理している実績がありました。
またモニタリング・監視については、オンプレミス環境のときから導入されているDatadogとCronitorを引き続き利用しています。
移行で直面した課題
移行にあたっては下記のような問題がありました。
認証・認可機構が複雑になっている
AWS移行前はアプリケーションの前段にオンプレミス環境のNginxがあり、ここでアクセスを捌いたりユーザー認証をしたりしていました。また、認可については別に独自の社内システムがありそれを利用していました(こちらの認可の機構は現在も利用しています)。
認証の機能をNginxからALBに移行するにあたり、ALBの認証機構を利用するようにしました。ALBでは下記のように簡単にOIDC認証をかけることができます。
オンプレ時代の認証では、何らかの利便性を図るために導入されたものの、リモートワークになった今では不要と思われる分岐処理がありました。例えば、「オフィスからのアクセスだった場合(VPNを含む)」「それ以外の場所からのアクセスだった場合」についての分岐などです。こちらについては、この機会に要不要を確認して削除しました。
本来はALBのこの機能を利用して認証と認可を同時に行うことも可能です。認証・認可の実装の整理については別途で改善活動が進んでおり、いつかブログで紹介できるかもしれません。
処理に時間がかかるエンドポイントがあり、ALBのIdle Timeoutのデフォルトでは足りなかった
ALBのデフォルトのIdle Timeoutの設定値は60秒です。本来はこれに合わせてアプリケーションの実装を考えるべきですが、オンプレNginxではさまざまな事情からIdle Timeoutを300秒(5分)に延ばしていました。これを前提に、Timeoutを考慮しない実装になっている箇所がありました。
60秒以内にレスポンスが返らず、またKeep Aliveパケットも送らないままだと、ALBの側からコネクションが切断されてしまいます。
移行後、これに起因する障害が起こりました。
この問題については、いったんALBのIdle Timeoutを延ばすことで対応しました。障害とその原因についてアプリケーションエンジニアの方に共有したところ、後日時間を取って実装を調査・修正してくれたので、現在は10秒程度でレスポンスが返ってくるようになっています。
非同期処理用のdelayed_jobのワーカーがバッチサーバー上で起動している
今回移行したシステムにはほとんど非同期処理がありません。しかし、とある一括で行われるバッチ的な処理(rakeタスク)のみ、delayed_jobを利用して非同期で実行されていました。このdelayed_jobのワーカーが「非同期処理を利用するのは特定の一括処理(rakeタスク)のみである」という理由でバッチサーバー上で起動していました。
AWS移行時にバッチはEventBridgeに移行したので、従来のような常時起動しているバッチサーバーはなくなります。また、本来非同期処理用のワーカーがバッチ用のサーバーに同居しているのも妙な状態だったので、ECSサービスを分離し、非同期処理のワーカー用に構築して対応しました。
AWS移行による副次的な効果
オンプレ時代は、「インフラのリソースはインフラチームの持ち物」「アプリケーションはアプリケーションチームの持ち物」という、権限上・意識上の壁がありました。何か変更したいことがある場合、お互いにチケットを切り、相手のチームに依頼して作業してもらうこともよくありました。
しかしAWS移行によってお互いに協働がしやすい構成になり、インフラエンジニアがアプリケーションのリポジトリにPull Requestを出したり、アプリケーションエンジニアがTerraformや監視のリポジトリにPull Requestを出すのが普通になりました。
また、オンプレ時代の潤沢なメモリや独自の設定値に合わせてゆるい実装をしていた部分が、AWS移行により顕在化しました。移行の作業効率を下げる不要な処理やデッドコードも見つかったため、そのまま移行せず削除するなど掃除をしながら移行を進めています。
こちらについても、インフラエンジニアとアプリケーションエンジニアの間で問題意識を共有し、実装を改善する動きが生まれています。協働して移行を進めることで、お互いに理解が深まり、改善に向けた議論や行動を以前よりも気軽に起こせるようになったと感じます。
サービスの信頼性向上のためにインフラエンジニアとアプリケーションエンジニアがお互いに越境する体制ができつつあります。
おわりに
今回の移行でもロードバランサーのIdle Timeoutが長いことを前提としている実装などが見つかりましたが、他にもAWS移行で見えてきた課題がいくつかあります。
- オンプレミスの潤沢なリソースを前提にしたメモリをモリモリ使う実装がある
- 連続する処理のフローをがんばってCronで表現したバッチ処理がある
- 数分ずつ実行時間をずらしてフローを表現している
- 一つのバッチがこけた場合、後続の処理がどうなるのかの調査が大変
2つ目の事例はAWS StepFunctionsを利用するときれいに書けそうですね。
このように、まだまだ改善の余地があります。その中にはAWSのマネージドサービスを利用することでシンプルな構成にできるものもありそうです。
リブセンスでは、AWS環境での開発やアプリケーションの性能改善に取り組みたいエンジニアの方、SREを実践したい方をお待ちしています。