

概要
技術部インフラグループの春日です。
2024年上期現在、弊社ではオンプレデータセンターで稼動しているサーバーのクラウド移行を進めており、 2024年1Qの時点で大半はAWSへの移行が完了しています。
本記事では社内で古くから運用し続けているメール配信サーバーのバウンスマネジメントに使用するアドレス帳データをクラウド移行した件について振り返ります。
メール配信サーバー自体のクラウド移行に関しては本記事では触れません。
以降の章ではメール配信サーバーを自前で運用している背景やクラウド移行前後での構成比較、および移行後のシステム詳細について触れていきます。
なお記事内ではEメールのことをメールと呼称します。
背景
そもそもメール配信サーバーを自前で運用している理由ですが、 大量配信用途におけるコストパフォーマンスの良さが挙げられます。 弊社が利用している商用メール配信サーバーの処理性能やライセンス料、運用コストなどを天秤に掛けた結果です。
メール配信サーバーを運用する事業者はメールの送信先に気を使う必要があります。 二度と届かない宛先やスパム系ドメインなどに送り続けるとメール配信サーバーの「評判」が下がり続け、 最終的にBANされて1通も届かなくなってしまうリスクがあります。
このリスクを未然に防ぐため、一度送ったメールアドレスと送信結果の情報を保存し続けて次回からの送信時に参照し、 届かない宛先や送ってはいけないドメインなどは送信をブロックして送らないように管理する必要があります。
その管理用データが「ブロックすべきアドレス帳」です。
用語的にはメールが届かないことをバウンスと言います。 一時的なソフトバウンスと恒久的なハードバウンスの2種類があり、これらはSMTPレスポンスコードで分類できます。 一般的にはソフトバウンス3回でハードバウンス扱いにするケースが多いようです。
メール配信サーバーの運用者はそのバウンスレートを約2%以下に保ち続ける責務があります。 単純計算で100通送ったうちの2通までがバウンスを許されます。
そしてバウンスレートを悪化させないように管理することをバウンスマネジメントと言います。 sendgrid.com
バウンスマネジメントにおいて弊社ではメール配信サーバーとアドレス帳データは私が所属するインフラグループで運用しており、 他事業部のシステムからそのサーバーとデータを使う形を取っています。
しかし、次の章でも触れますがオンプレ時代の構成をそのままクラウド側に持っていくには厳しい状態が続いていました。
移行
この章では弊社のメール配信サーバーの利用方法について、オンプレ側とクラウド側での移行前後の構成比較をします。
今回のクラウド移行ではオンプレ構成における運用上の課題が多過ぎたため、Lift and Shiftの両方を一度に実現しました。 また、メール配信サーバー自体のクラウド移行は一足先に完了していたため、今回の移行はその状態からスタートしました。
移行前の構成 (MySQL, PHPバッチ)
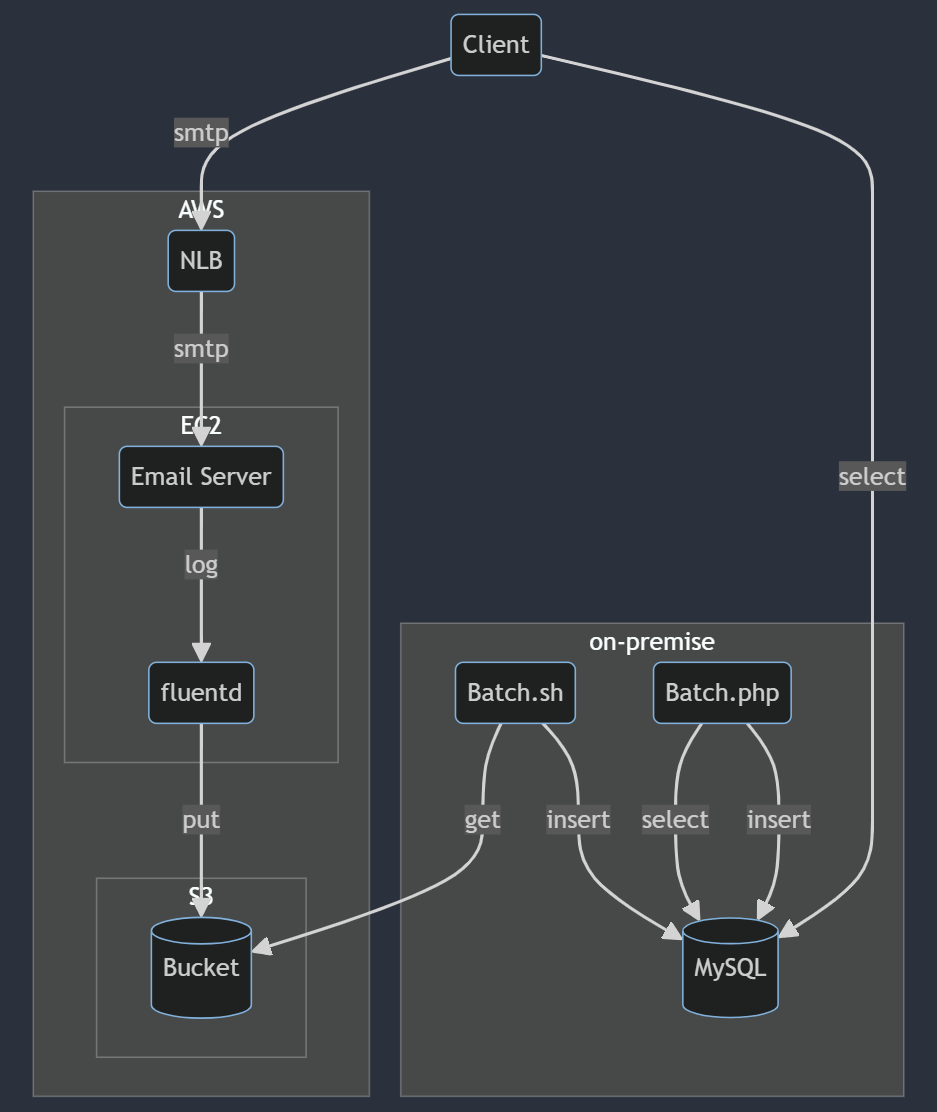
オンプレ時代の構成ですが、まずメール配信サーバーのログをfluentd経由で一度S3バケットに保存し、オンプレサーバー側から定期的にShellScriptでダウンロードしてMySQLの一時テーブルに登録していました。 そしてその一時テーブルを定期的にPHPバッチで集計処理してブロックすべきアドレスおよびドメインのリストを生成していました。
なおMySQLサーバーはPercona XtraDB Clusterでマルチマスター構成を取っており、特に不自由なく運用できていました。 しかしPHPバッチ処理が社内でレガシーと化しており、何か障害が発生したときに対応できる人員が限られていました。 PHPのバージョンが古過ぎるというのもありますが、テストもCIもステージング環境もログ出力もありませんでした。 定期実行の設定もcrontabで、何かしら変更を加える際は全て手動オペレーションでした。
そして一番の課題となっていた設計が、そのアドレス帳データを使うクライアント側が直接DBに接続してSELECTしている点でした。 事業部的にも管轄が分かれており、今回のクラウド移行ではそこを疎結合に変える改善が求められていました。
移行後の構成 (DynamoDB, Kinesis)
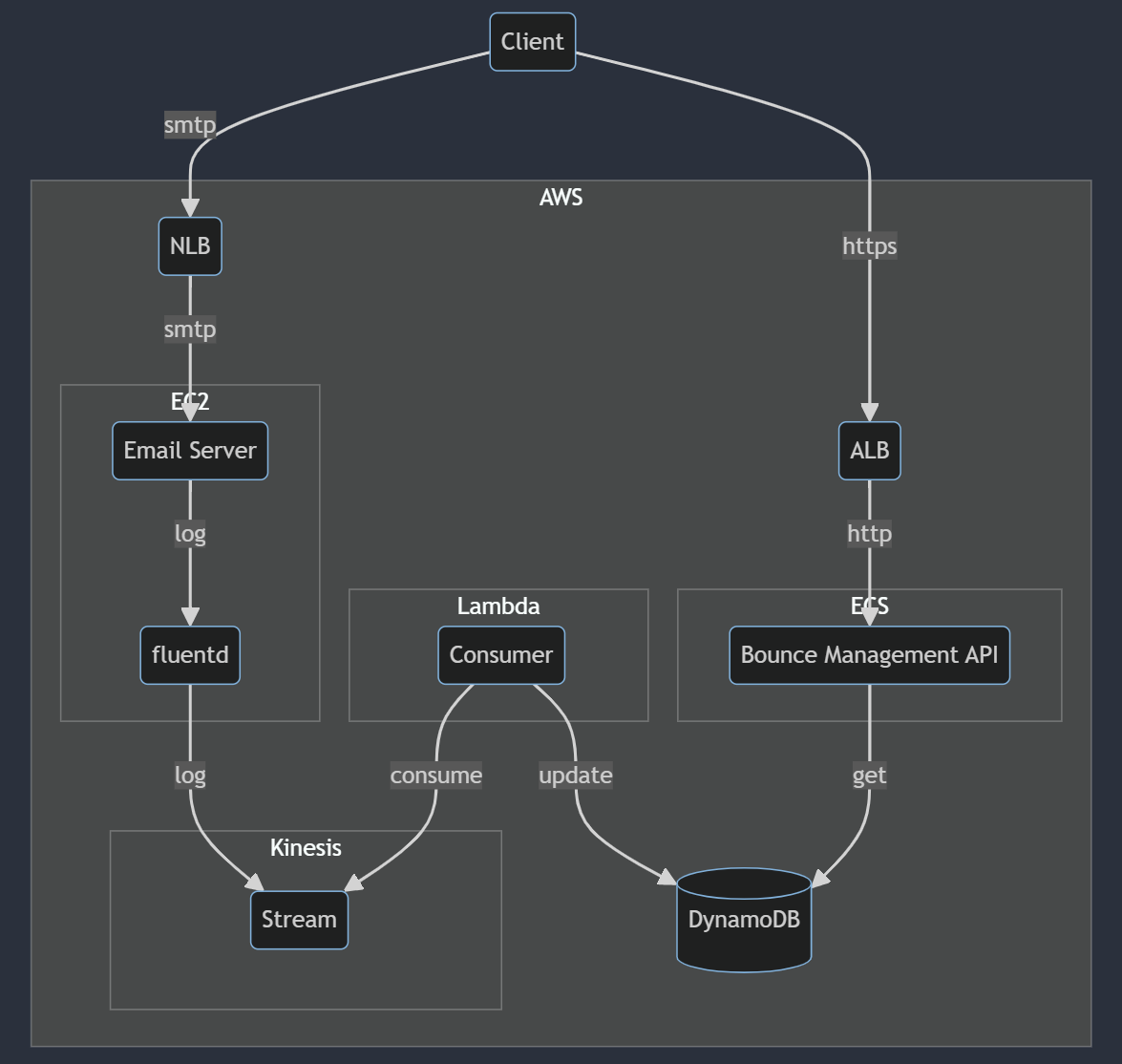
クラウド移行後の構成はKinesis StreamとDynamoDBを利用してほぼリアルタイムにバウンスマネジメント用のデータを生成する形に変更しました。
メール配信サーバーのログをfluentd経由でKinesis Streamに流し、Lambda関数でconsumeしてDynamoDBのテーブルに対してアイテムを更新します。
DynamoDBにはメールアドレスごと、ドメインごとの2つのテーブルを用意しました。 それぞれ送信成功、ソフトバウンス、ハードバウンスの件数を保持するシンプルなテーブル設計です。
| id | success | soft_bounce | hard_bounce |
|---|---|---|---|
foo@example.com |
0 | 0 | 1 |
bar@example.co.jp |
0 | 0 | 1 |
| id | success | soft_bounce | hard_bounce |
|---|---|---|---|
example.com |
0 | 0 | 213 |
example.co.jp |
0 | 0 | 57 |
そして課題であったクライアント側との疎結合化として、バウンスマネジメント用のAPIを新規に実装・構築してクライアント側からはHTTPで参照してもうらう形にしました。
移行の段取り
今回の移行にあたり、一番注意しないといけなかったのがバウンスレートの維持でした。
移行前後のアドレス帳データに大幅な差異があると、バウンスレートが悪化したりメール送信数に極端な変化が生じてしまいます。 これらはメール配信サーバーの評判が悪化するだけでなく、ビジネス毀損やエンドユーザー様への不利益にも繋がります。
そこで移行を始める前に、まずオンプレ版とクラウド版の双方のデータをサンプリングして突合試験を実施しました。
次にバウンスマネジメント用データを利用するクライアント側の実装にて、オンプレDB側とクラウドAPI側へのアクセスを確率的に振り分けられるようにしました。
そして移行割合を環境変数で設定できるようにして、徐々に割合を上げては様子見してを繰り返しながら最終的に100%クラウド側を参照する状態に持っていくようにしました。
if (0から99までのランダムな整数 < 移行割合) {
API参照
} else {
DB参照
}
なお弊社でのバウンスレートのモニタリングですが、メールの配信ログは別途Treasure Dataにも流していてredash上でダッシュボードを作成しています。 加えて日次の集計結果を毎朝Slack通知しています。ここらへんは将来的にはDatadog連携などを検討中です。
次の章ではクラウド移行後の構成に関してより具体的に説明します。
詳細
ここではクラウド移行後のシステム構成の詳細について話します。 構成要素は以下の3つです。
- メール配信サーバーのログを元にバウンスマネジメント用データを更新するストリーミング処理
- メール送信をするクライアント側から送信前に参照されるバウンスマネジメント用API
- APIを叩くクライアント側の実装
ストリーミング処理
メール配信サーバーのログをfluentdでJSON化し、Kinesis Streamに流してLambda関数でconsumeしており、その関数はGoで実装しています。
LambdaではGoの標準ランタイムサポートが廃止されるみたいで、カスタムランタイムのコンテナイメージ版で実装する必要がありました。 (個人的には手軽なZIP形式のアップロードが気に入っていたため格下げに感じています...)
また、Lambda関数実行部分の内部RPC依存がなくなるみたいで、新しい方はよりシンプルなアーキテクチャに変わっています。
Goのビルドオプションのタグに lambda.norpc を付けてあげるとライブラリの方で動作が変わり、新しい方の関数実行形式で呼ばれるようになります。
Goでビルドした実行ファイルで処理が完結するため、軽量のベースイメージでビルドできます。
コンシューマーの責務はストリームのJSONデータを元にSMTPレスポンスを判別し、 送信成功・ソフトバウンス・ハードバウンスを判定してDynamoDBのテーブルのアイテムを更新することです。
再掲ですがメールアドレスごと、ドメインごとの2つのテーブルを作成しており、件数をカウントするだけのシンプルな設計です。
| id | success | soft_bounce | hard_bounce |
|---|---|---|---|
foo@example.com |
0 | 0 | 1 |
bar@example.co.jp |
0 | 0 | 1 |
| id | success | soft_bounce | hard_bounce |
|---|---|---|---|
example.com |
0 | 0 | 213 |
example.co.jp |
0 | 0 | 57 |
実装的には AWS公式のSDK v2 をそのまま利用しており、DynamoDBの更新式を利用してアトミックにインクリメントしています。 github.com docs.aws.amazon.com docs.aws.amazon.com
なおメールアドレスごとのテーブルに限り、送信に成功したときはソフトバウンスとハードバウンスの値をゼロにリセットしています。 これでソフトバウンスからの復旧ができるようになります。
また実際はメールアドレスはハッシュ化してテーブルに保存してあり、デフォルトでマスキングされた状態にしてあります。 そのためテーブルをSCANするような使い方は想定していません。
ところで、しばらく運用を始めてから遭遇したエラーの1つに、DynamoDBのホットキー制限のエラーがあります。
Throughput exceeds the current capacity of your table or index. DynamoDB is automatically scaling your table or index so please try again shortly. If exceptions persist, check if you have a hot key: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-partition-key-design.html
これは課金形式がオンデマンドでも発生するスロットリングで、我々のユースケースだと発生要因は自明でした。
我々はDynamoDBにメールアドレスごと、ドメインごとの2つのテーブルを作成しています。 前者は1つのアイテムに集中的に何度も更新が発生するケースはないですし、そもそも発生すべきではありません。 しかし後者はユーザー数の多い有名なドメインであれば十分有り得ます。
この問題に対し、ホットキーのスロットリングが発生したらしばらく更新をスキップするように対応しました。
コンシューマーはLambda関数なので基本的にステートは保持できません。 なのでなるべくLambda関数実行の並列度を下げて1シャード1関数の状態にし、 1回の実行でより多くのレコードを集計して書き込み処理を集約できるよう調整した上で以下のようなスロットリング検知機構を設けました。
package example import ( "sync" "time" ) type Throttle struct { valve sync.Map wait time.Duration } func NewThrottle(wait time.Duration) *Throttle { return &Throttle{valve: sync.Map{}, wait: wait} } func (th *Throttle) Started(key string) bool { if i, ok := th.valve.Load(key); ok { if t, ok := i.(time.Time); ok && time.Since(t) < th.wait { return true } } return false } func (th *Throttle) Start(key string) { th.valve.Store(key, time.Now()) }
アイテム更新時にスロットリングのエラーを検知したら #Start 関数を呼んでそのアイテムを登録し、
#Started 関数が true を返す間だけ更新処理をスキップするように実装しています。
APIサーバー
メールを送信したいクライアントが送信前にアドレスをブロックすべきか否かを判断するために参照するAPIを新規にGoで実装し、 ECS Fargateで動かしています。
エンドポイントは1つで、メールアドレスを指定してそのバウンス情報を返すのみです。 これ以上ないシンプルなAPIですので、特にWebフレームワークは利用せずにGoの標準パッケージのみで実装しました。
そしてOpenAPI バージョン3で仕様を定義し、Swagger UIを社内公開したりクライアント側でコードを自動生成できるようにしました。 swagger.io
このバウンスマネジメント用APIの使われ方ですが、メルマガなどのメールの大量配信処理はバッチ処理である場合が多く、 一度に1000件程度ずつ処理をするケースが大半です。
なので GET のみのエンドポイントだとURLが長過ぎて 414 エラーになってしまう懸念があったため POST でも指定できるようにしています。
今までRDBMSにSELECTして実現していたことをHTTPでやる形に変えるため、パフォーマンス劣化の懸念がありました。 そこで事前に vegeta を利用して負荷試験を実施しました。
本番での実際の使われ方を想定してメールアドレスを1000件ずつ指定して実施したところ、 許容範囲内のレイテンシで秒間100リクエスト程度は余裕で裁けることがわかりました。 (もちろんサーバーの台数や割り当てるリソース量にも因ります)
$ cat requests.txt | vegeta attack -header='user-agent: vegeta' -rate=100 -duration=60s | tee results.bin | vegeta report Requests [total, rate, throughput] 6000, 100.02, 99.97 Duration [total, attack, wait] 1m0s, 59.99s, 29.768ms Latencies [min, mean, 50, 90, 95, 99, max] 18.588ms, 34.667ms, 31.861ms, 45.631ms, 51.828ms, 73.974ms, 312.429ms Bytes In [total, mean] 594120000, 99020.00 Bytes Out [total, mean] 204030000, 34005.00 Success [ratio] 100.00% Status Codes [code:count] 200:6000 Error Set:
限界を探ろうと同時接続数を増やしていったところ秒間200リクエストで取り零しが発生し、 そのときGoroutinesの数が1万近くに跳ねてました。
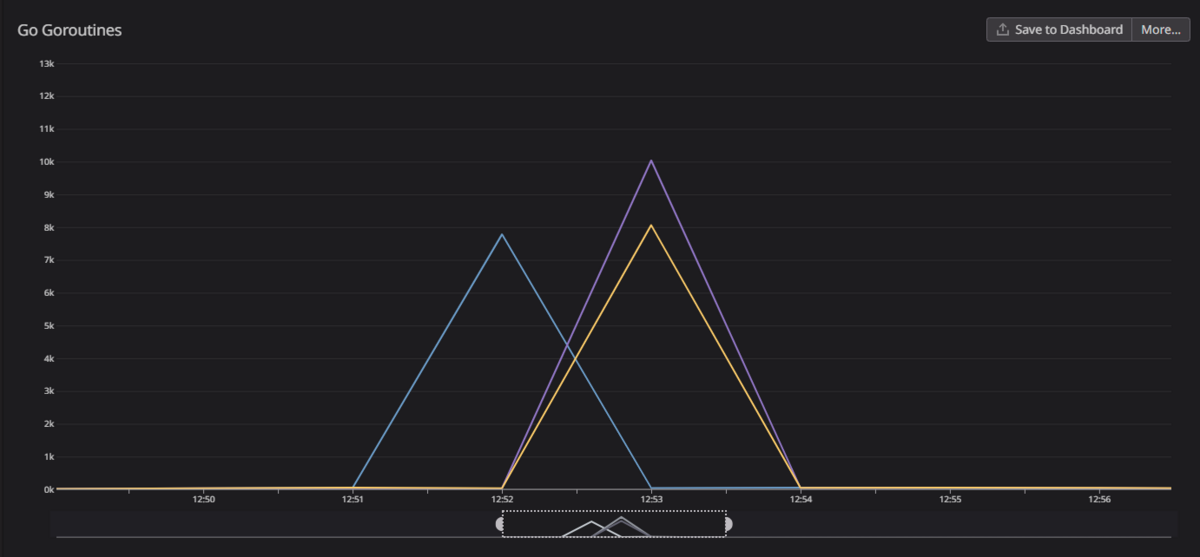
DynamoDBのテーブルは2つあり、DynamoDBのBatchGetItemオペレーションは一度に最大で100件ずつしか取得できません。 そのためリクエストごとにGoroutineが生成され、そのGoroutineがさらにGoroutineを生成する実装になっています。
GC負荷を考慮して一部の実装に sync#Pool も利用しています。 その点も含めてGoroutineが増え過ぎるとオーバーヘッドも大きくなってしまいます。
そこで netutil#LimitListener を使って最大同時接続数を制限し、Goroutines生成のスパイクを抑制することにしました。 ソースコード を見る限りbuffered channelで制御するシンプルな実装で、 このリスナーを利用することで acceptしてからserveする無限ループ 内でのGoroutines生成に制限を掛けられるようになりました。
しばらくして移行割合を徐々に上げていったところ、ストリーミング処理と同じくAPI側でもホットキーのスロットリングが発生する可能性が出てきました。
素朴な実装だとドメインごとのアイテムが格納されているテーブルに対するアクセスに偏りが出てしまいます。 ユーザー数の多いドメインに対する読み込みが短時間で高頻度に発生してしまいます。
そこで以下のライブラリを使用してDynamoDBから取得したアイテムを in-memory にキャッシュする実装を追加しました。
ちなみにDynamoDBには透過的に組み込めるマネージドなキャッシュサービスが存在しますが、 我々の使い方だと基本的に予想できるアクセスパターンであったため、構成のシンプルさを優先して今回は利用を見送りました。
APIクライアント
バウンスマネジメント用APIを使う側のコードは Swagger Generator で自動生成しました。 しかし結論から言うとそのままではまともに動くコードではありませんでした。
OpenAPI定義の書き方が良くなかったり、コード生成時の私のオプション指定が足りていなかった可能性も大いにありますが、 APIトークン認証周りの実装があったりなかったり、JSONのパース処理がサイレントに失敗していたりしました。
あくまで自動生成コードと割り切って、そこから先はちゃんと自分たちでテストを書いて整形していく必要がありました。 将来的にAPI定義の変更が発生する度に自動生成に頼るのは厳しいと判断し、 なるべくDRYに書き直した上で手動でメンテナンスし易くなるよう加工していきました。
今回のクライアント側の言語はRubyとTypeScriptでした。 どちらもリンターからボコボコに指摘されるため、自動修正できない部分は言語のバージョンUP対応時にネックになりそうな記法を重点的に手動で直していきました。
後は先に述べた通り、段階的に移行できるようにアクセス先を新旧で振り分けられる分岐を仕込みました。
分散システムでサービス指向アーキテクチャのDynamoDBは専有インスタンスが動いている訳ではないため、 オンデマンド課金でも各種スロットリングが発生し得ます。
段階的な移行は我々の使い方だとキャパシティ的に余裕がどれくらいあるかを見定めるためでもありました。 repost.aws docs.aws.amazon.com
あと過渡期は念のためクラウド側のAPI参照が何らかの理由でエラーになった場合にオンプレ側のDBを参照するようフォールバックも仕込んでおきました。
移行を終えて
バウンスマネジメント用のアドレス帳データをクラウド移行してしばらく経ちましたが、今のところバウンスレートや送信数に変化は見られません。
しかし今後は「メールが届かない」などの問い合わせが少なからず発生する可能性はあります。 これは移行前も低頻度で発生していました。
まだ使われていないですが、実はバウンスマネジメント用のAPIにブロックされているメールアドレスを解除できるエンドポイントも生やしています。 もし問い合わせ頻度が上がるようであれば権限を管理した上でSlack連携などで運用改善できないか検討します。
また、ソフトバウンスとハードバウンスの判定ロジックやブロックすべきか否かの判断箇所でまだ煮詰め切れていない部分も残っています。 それとアドレス帳データが不正に更新されてしまった場合のリカバリ方法も検討が必要です。
今回の移行でテストやCIやステージング環境が当たり前に存在するようになりました。 システム改修時の心理的ハードルや障害リスクは下がったと言えるため、日々の運用で鍛えていくことが現実的になって一先ず良かったと思います。
最後に
以上、弊社でのメール配信周りのシステム事例紹介およびクラウド移行時の振り返り記事でした。 ここまでお読みいただき、ありがとうございます。
弊社のメール配信サーバーは商用ソフトウェアを利用しています。 クラウド移行が進んでオンプレ環境からどんどんサーバーが消えていく今、 将来的には全社横断で利用するようなプラットフォームをインフラグループが自ら生み出して育てる世界線に行きたいなぁ、 と個人的に考える今日この頃です。
ともあれインフラグループは引き続き他事業部と連携してクラウド移行後のコスト・パフォーマンス最適化などを進めて参ります。