
こちらはLivesense アドベントカレンダー 2020 およびKubernetes3 アドベントカレンダー1日目の記事です。
こんにちは、転職会議のSREのかたいなかです。
転職会議では2020年の一年間をかけてインフラ基盤をECSからEKSに移行してきました。
この記事では構築したEKS基盤やECSからの移行の中で工夫した点を紹介します。
なぜEKS移行?
古くなっていたECS基盤を刷新する上で、ECSで再度作り直すのではなくEKSを選んだのは主に以下のような理由です。
- IaCを更に推し進めGitOpsの考えを採用し、開発者がSREにレビュー以外で依存することなく主体的にインフラを変更できる状態を作るため
- ArgoやIstioといったKubernetesネイティブに開発されているツールを採用することでの恩恵を将来的に受けられるようにするため
- 純粋な技術的興味
採用を決めた当時は技術的興味が一番大きな動機だったかもしれません。
構築したEKS基盤
構築した基盤を観点ごとに紹介します。
CI/CD
- Flux
- Weave Cloud
- チャットボット
Fluxを用いてGitOpsに基づくCI/CDを実現しています。ArgoCDではなくFluxを選んだのは、以下のような理由がありました
- Fluxは新しいイメージのデプロイとYAMLの変更の適用の機能のバランスが取れている
- KubernetesのYAMLだけでなくイメージのデプロイのための機能がある
- 「
master-というプレフィックスがついたタグのうち最新のものを自動でデプロイ」等 - 「コマンドを叩くことで特定のブランチから作成されたイメージをデプロイ」等が実現可能
- 「
- ArgoCDは新しいイメージのデプロイを行う部分は自作の必要あり
- GUIやYAMLの変更周り(差分の確認等)が優れているだけに惜しい
- 現在はArgoCD Image Updaterが開発されているが当時はなかった
- KubernetesのYAMLだけでなくイメージのデプロイのための機能がある
FluxはGitHub上のYAMLファイルを定期的にクローンし、差分をKubernetesクラスタに適用します。また、YAMLファイルだけでなくECR上の新しいイメージを定期的にフェッチし、設定によって新しいイメージを自動でデプロイしたりできます。新しいイメージをデプロイする際には新しくデプロイするイメージのタグの情報をGitHubに自動でコミットするのがFluxの特徴的な動作です。
転職会議では、ステージング環境は新しいイメージがビルドされ次第デプロイ、本番環境ではSlackのチャットボットからコマンドが叩かれたタイミングでデプロイするようにしています。
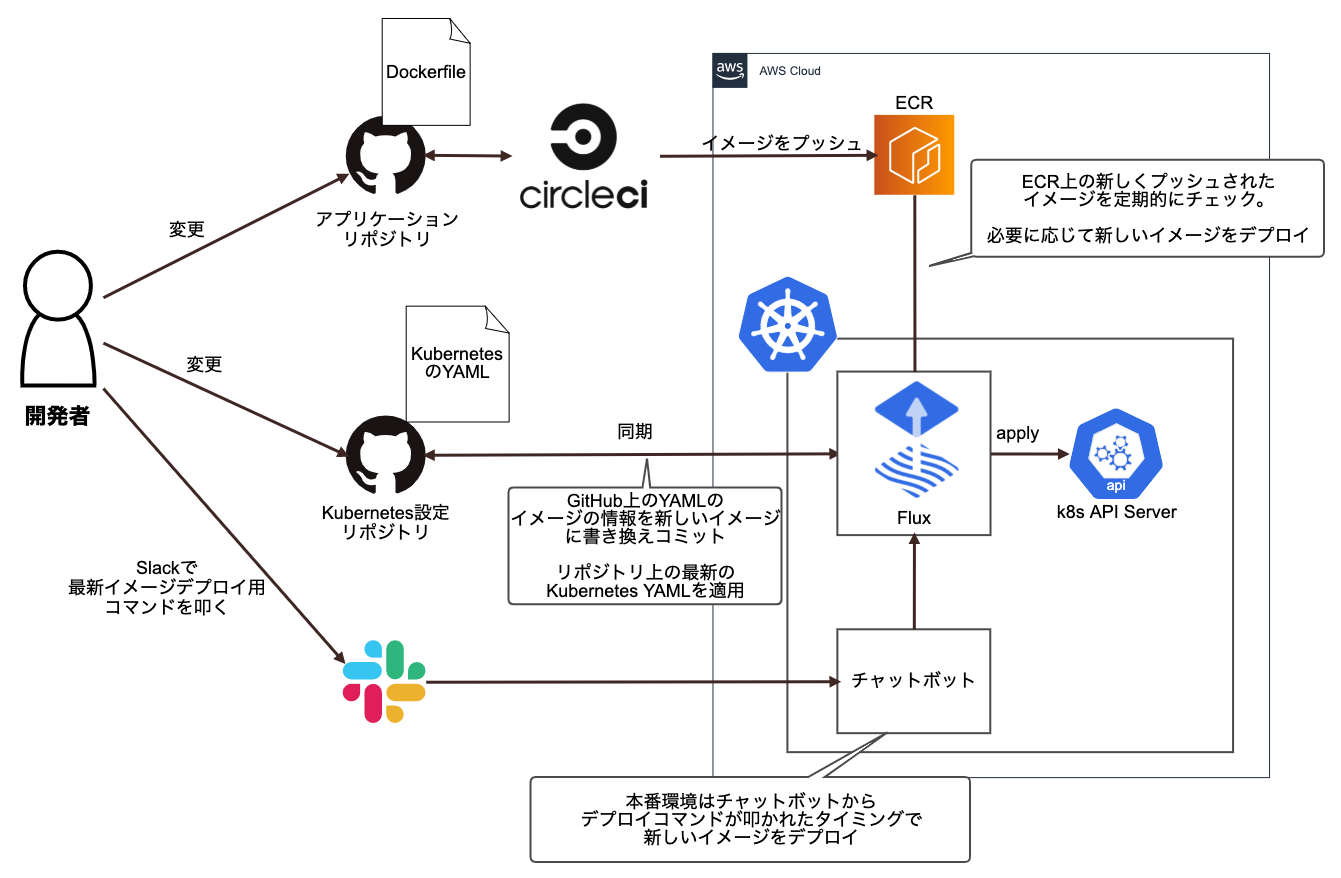
FluxでのCI/CDでは、Dockerイメージをビルドするための各マイクロサービスのリポジトリとは別に、KubernetesのYAMLを集中管理するリポジトリを作成しました。リポジトリのディレクトリ構造は以下のようになっています。
.
├── README.md
├── clusters(Fluxでデプロイするためのファイル群)
│ ├── production(本番のFluxのデプロイ対象のディレクトリ)
│ │ ├── flux-patch.yaml
│ │ └── kustomization.yaml (このkustomization.yamlのbasesですべての本番デプロイ対象の`xxxxx/overlays/production` を列挙)
│ └── staging(ステージングのFluxのデプロイ対象のディレクトリ)
│ ├── flux-patch.yaml
│ └── kustomization.yaml (このkustomization.yamlのbasesですべてのステージングデプロイ対象の`xxxxx/overlays/staging` を列挙)
├── manifests
│ ├── default(namespaceごとのディレクトリ。これ以下Kustomizeで管理されたディレクトリが並ぶ)
│ │ ├── api-xxxxx
│ │ │ ├── base
│ │ │ └── overlays
│ │ └── api-yyyyy
│ │ ├── base
│ │ └── overlays
│ ├── kube-system(同じくnamespaceごとのディレクトリ)
│ │ ├── external-dns
│ │ │ ├── base
│ │ │ └── overlays
│ 略 略
├── scripts(./templates以下のファイルを展開するスクリプト等)
| └── 略
└── templates (アプリケーションの種類ごとにテンプレートを用意)
├── argo-workflow
│ └── 略
├── cronjob
│ └── 略
└── deployment
└── 略
現在のFluxの弱点として、ナイーブに導入すると、一つのリポジトリの一つのディレクトリしか対象にできないという問題があります。ArgoCDであればApplicationという単位に区切って扱えるのですがFluxではそれができません。
これにより、デプロイ対象のYAMLが増えるにつれてKustomizeのビルド等にかかる時間が長くなってしまいWeave Cloudからのリクエストがたびたびタイムアウトしてしまったり、YAMLが壊れているとすべてのアプリケーションのデプロイに影響が出てしまう問題が発生してしまっています。
このあたりは、現在開発されているFlux v2で解決される見込みですが、ArgoCDもArgoCD Image Updaterの開発を進めており、これらを利用してCI/CD基盤を再構築する際に解消したいと考えています。
監視・ログ
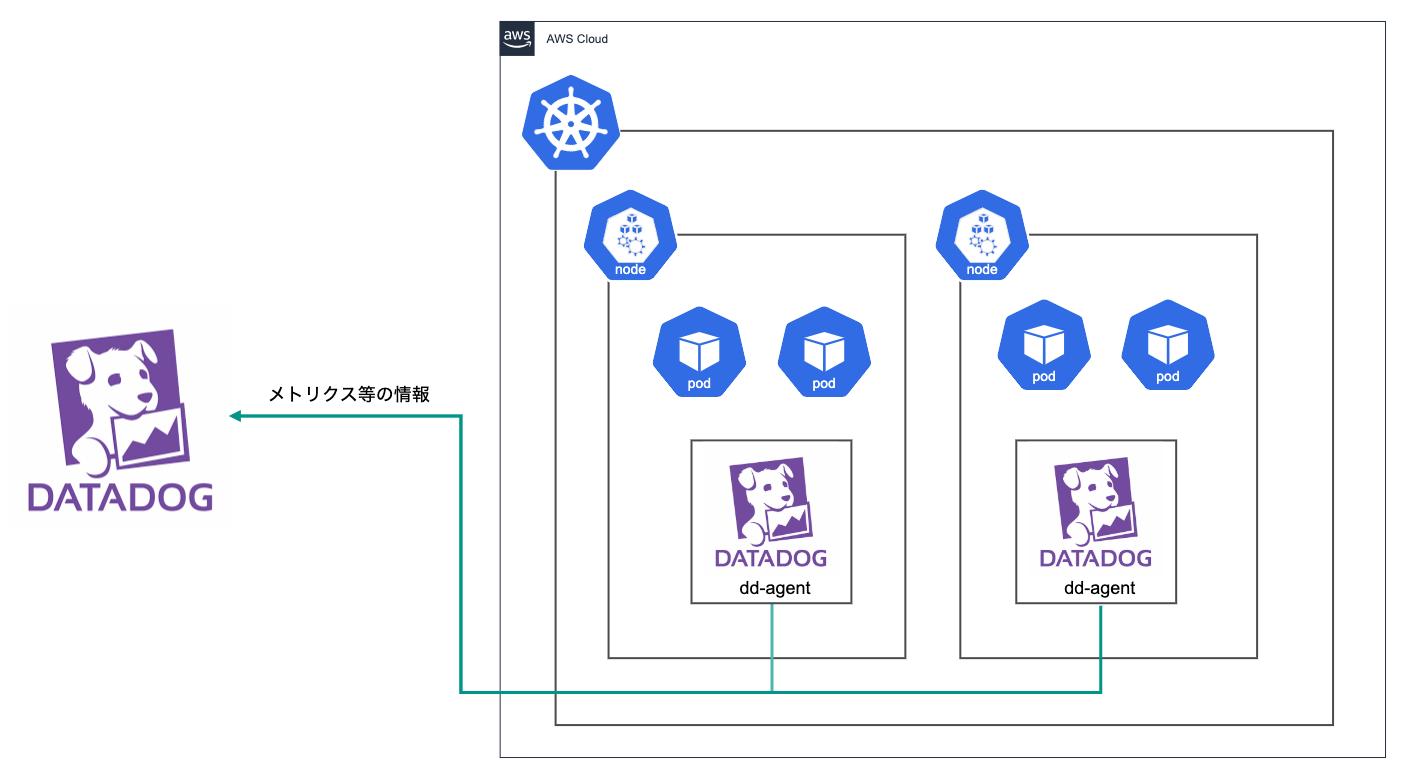
Kubenetesの監視はDatadogによって行っています。DaemonSetとしてデプロイしたDatadogエージェントがメトリクスやイベントの情報を収集し、Datadogに送信しています。
Datadogによる監視では、システムコンポーネントのPrometheusエンドポイントからメトリクスを収集することもでき、AWS Load Balancer ControllerやSealedSecrets等の監視でとても便利です。 詳しくはこちらの記事を参照ください。
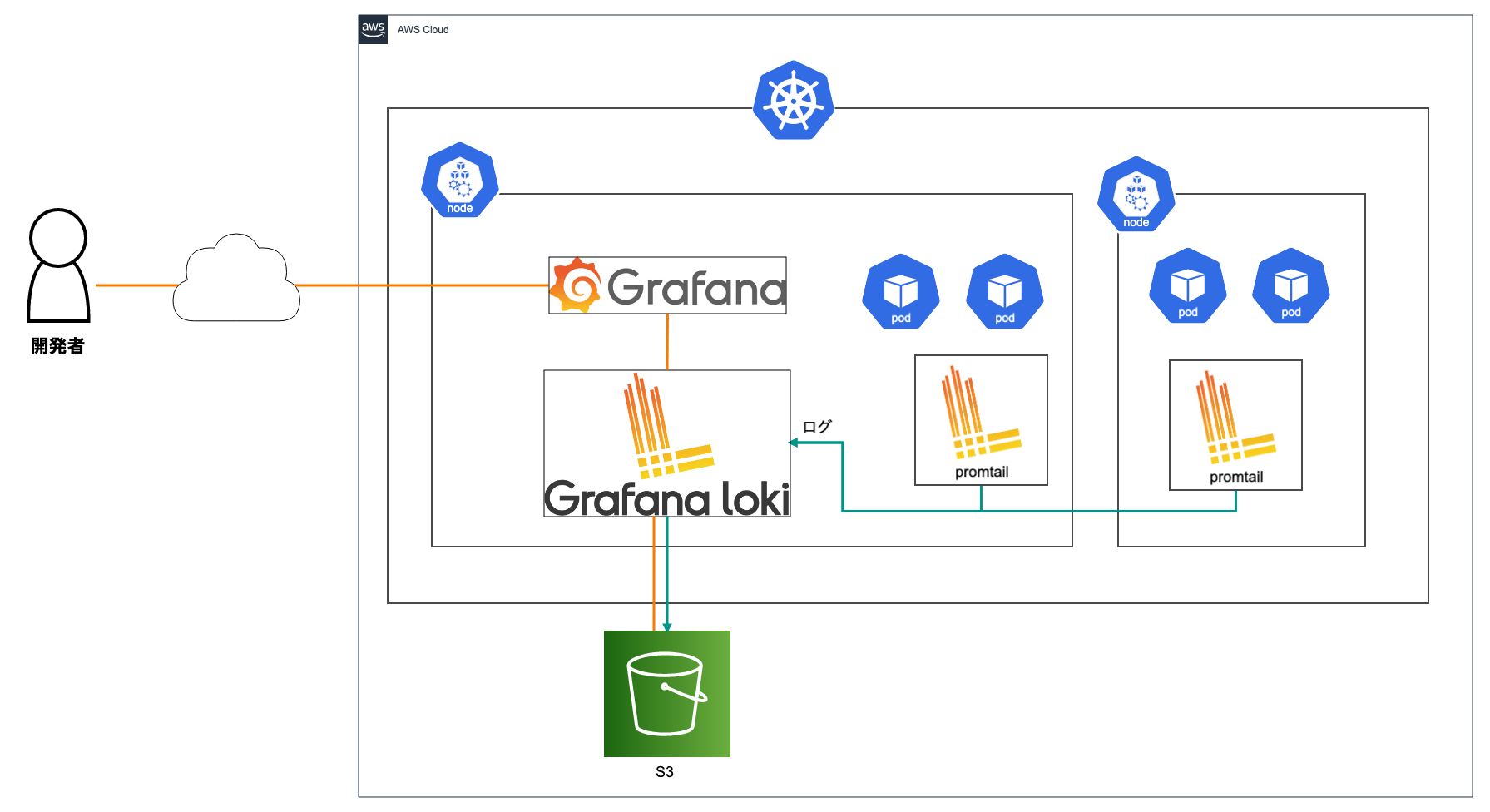
ログ基盤はGrafana Lokiにより構築しています。各ノード上にDaemonSetとして展開したpromtailというエージェントが集めたログをS3をストレージにしたLokiで保存し、Grafana経由でログを見られるようにしています。
自動スケーリング
- Cluster Autoscaler (ノードを自動で増減)
- Horizontal Pod Autoscaler(Podを自動で増減)
ECSでもインスタンス数やタスク数の自動スケーリングは行えるのですが、ECS基盤を使っていた当時は手が回らず自動でスケーリングさせる設定を導入できていませんでした。KubernetesではCluster AutoscalerおよびHorizontal Pod Autoscalerを使用すると簡単に自動スケーリングが行えて便利でした。
HPAに関しては外部からのリクエストを受け付けるPodのみPodのCPU使用率でのみスケーリングしているのですが、将来的には、ワーカーのPodをSQSのキュー内のメッセージ数ベースで増減させたいと考えています。
AWSのリソース管理
ECSを使用していた頃はALBやRoute53の設定が簡単に行えず、新しいアプリケーションのデプロイのたびにSREが作業を請け負うといったことが発生していました。AWS Load Balancer ControllerとExternalDNSを採用したことで、テンプレートで用意したデフォルトの設定を利用しながら開発者がセルフサービスでALBやRoute53の設定を行えるようになりました。
また、AWS Load Balancer ControllerとExternal DNSのPrometheusエンドポイントから取得したメトリクスをDatadogで監視するようにしています。これにより、例えばALB関連で誤った設定をしてしまいKubernetes上のIngressの設定と実際のALBの状態に差分がある状態となったときに気づけるようにしています。
クレデンシャル管理
Secret管理にはFluxのGitOps的なフローとの相性の良さからSealedSecretsを採用しました。暗号化されたクレデンシャルをSealedSecretsという名前のCustomResourceとしてクラスタにapplyすると、クラスタ内のSealedSecrets Controllerが暗号化された値を復号しSecretを作成します。
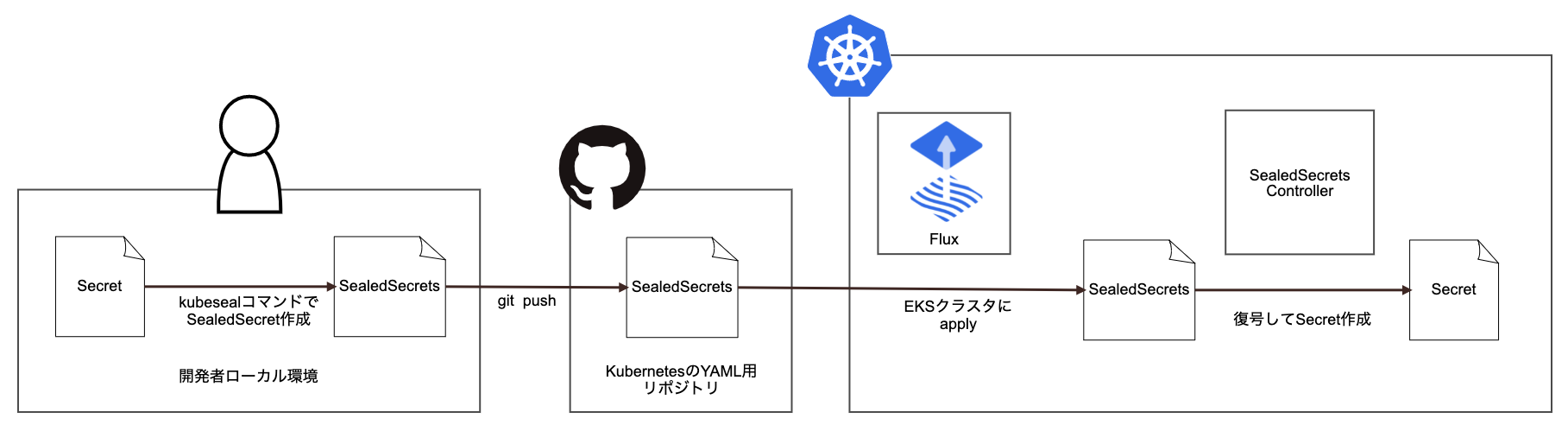
SealedSecretsではKMSによる暗号化に対応しておらず、Kubernetesクラスタ内に復号のための鍵を作成し保存します。そのため、これらの鍵が失われるとクレデンシャルの情報が失われてしまいます。このような自体を防ぐため、Veleroを導入しています。
SealedSecretsで暗号化するとまだKubernetesクラスタに適用していないレビュー時点で暗号化された値の正しさを検証しづらいためこの部分はデメリットだと感じています。
新規開発用のKubernetes YAMLテンプレート
なるべく開発者が初期構築から自走して利用できる状態にしたかったので、新しいアプリケーションを開発者がデプロイするときに使える、KubernetesのYAMLのひな形を生成するツールをGoで簡単なスクリプトとして用意しました。

進め方
Kubernetesの拡張性の高さやバージョンアップの速さのため、SREが2人の転職会議ではすべての可能性をきっちり検証しきった上でEKS移行するのは現実的に難しいと考えました。
そのため、以下のようにいくつかのステップに分けてそのとき必要になる最低限の機能を順番に揃えていくことをSREチーム内で意識を合わせながら進めていきました。これにより分析麻痺の状態に陥ったりせず着実にEKS化を進められたと考えています。
ガントチャートにすると以下のようになります。

それぞれのステップでは具体的には以下のようなことを行っていました。
- ステージング環境として使っても問題ないレベルのEKS基盤を目指す時期(2020年1月~2月)
- Kuberentesの社内勉強会
- FluxでのCI/CDのしくみの構築
- Kubernetes YAMLのテンプレート作成
- CI/CD周りの監視(デプロイ後PodがCrashLoopしてしまう場合など最低限のケースのみ)
- ノードの管理の方針を決める(EKS on Fargateを使う使わない等)
- 重要度の低いサービスを試験的にEKS移行
- 本番環境をEKS基盤に切り替えても問題ない状態までブラッシュアップする時期(2020年3月~4月)
- 障害事例調査
- Kubernetes YAMLのCI導入
- 全体的な監視の方針決定・実装
- 各マイクロサービス移行時の手順のドキュメント化
- HPA、Cluster Autoscalerの導入
- クラスタ更新の手順書作成
- 各マイクロサービスを順次EKSに載せ替えていく時期(2020年5月~2020年9月)
- モブプロ形式によるEKS移行会
- 各マイクロサービスを順次EKS移行
- マイクロサービスは全部で50個程度
- よりよいEKS基盤を目指す時期(2020年10月~現在)
- すべてのPod間の通信をALB経由でなくKubernetesのService経由で行うようにする
- Argo導入・既存のバッチ処理間の依存性を整理
- 以前からの懸案であったバッチ処理間の依存関係を整理するためArgo Workflowを導入中
進め方のポイント
マイクロサービスごとのEKS移行
EKS移行作業はマイクロサービスごとに一つずつ順番に進めていきました。
具体的には、ECSのServiceと紐付いたALBに向けているRoute53のレコードを、AWS Load Balancer Controllerで作成したALBに順番に向きを変えていきました。これにより移行時に発生する問題を局所化し問題発生時のロールバックも高速化でき、大きな障害が発生することなくEKS移行を終えることができました。
また、重要度が極めて高いサービスをEKSに移行するときには、一度にすべてのトラフィックを切り替えるのではなく、Route53のWeighted Rootingを利用し、EKSに向けるトラフィックの割合を増やすようにしました。
開発者への知識移転
EKS移行においてはECS時代の反省を踏まえ、開発者が自律して使えるインフラを作ることが大事だと考えていました。そこで、知識移転のための勉強会を手厚く行いました。
まず、Kubernetesの一般的な知識を伝達するための勉強会を1ヶ月半程度実施しました。
次に、一般的な知識が身についたところで今度は実際のKubernetesクラスタを触ってもらいながら理解を深める機会を作るため、現在開発を進めているサービスをSREの指導のもとで自分たちでEKSに移行してもらう会をモブプロ形式で実施しました。これにより、実際の業務と紐付けてKuberentesの知識を深めてもらえたのではないかと思っています。
可能な範囲でEKSに移すタイミングでアプリケーションの負債を返す
転職会議は息の長いプロダクトであるため、負債が溜まっているがなかなか手出しのできないサービスがいくつか存在していました。
次世代につながるインフラを作っていくため、なるべく負債を返済しながらEKS移行を行っていくことを意識しました。具体的には、不要となっているのに残っている環境変数の削除から古くなった外部連携用のバッチ処理の再実装まで可能な範囲で行いました。
オブザーバビリティの担保
EKS移行開始時点では転職会議ではDatadog APMが8割ぐらいのマイクロサービスに導入されている状態でした。Kubernetes化によりマイクロサービス間の通信がALBを介さなくなるとオブザーバビリティに問題が出ると考え、それぞれのマイクロサービスをEKS移行するときに、Datadog APMが導入されていない場合は先にAPMの導入作業を行うようにしました。
これからやりたいこと
CI/CDの安定化・高速化
Fluxの採用により当初はデプロイ等もスムーズに行えていたのですが、ひとつのFluxのエージェントですべてのYAMLを管理するようになっているため、ある一定以上EKS移行が進んだ際に、パフォーマンス面で問題が生じWeave Cloudからのリクエストがタイムアウトして画面からの操作が行えない問題が発生しました。
また、現在の状態では、一つのYAMLにまとめてからデプロイするという都合上、CIで拾いきれなかったYAMLの誤りによってすべてのリソースが一度に影響を受けてしまう可能性もあります。
現在のところ大きな問題にはまだなっていないのですが、このような状態は早めに解消したいと考えています。FluxはFlux v2の、ArgoCDはArgoCD Image Updaterの開発が現在進行中なのですが、これらの採用によってこのような問題は解決できると考えており、リリースを首を長くして待っています。
カナリアリリース・ABテストを支えるしくみづくり
ECSからEKSへの切替の中で、トラフィックを古いアプリケーションから新しいアプリケーションに順番にシフトさせることで大きなリリースのリスクを低減できることをSRE自身で身をもって実感しました。これをさらに推し進めて、開発者が自分たちでカナリアリリースしたり、今はコード側で制御しているABテストをインフラ側に寄せたりなど、柔軟なデプロイが行えるようにできないかと考えています。
Kubernetesを前提とするとIstioをはじめとしてたくさんの実現手法がありそうです。検証を進め大規模リリースや仮説検証を積極的に支えていけるような基盤にしていきたいと考えています。
EKSのKubernetesバージョンアップの効率化
現在はAWS Load Balancer ControllerやExternalDNS等のYAMLが生で転職会議内のリポジトリで管理されており、差分のチェック等がEKSクラスタのバージョンアップ時の負荷につながっています。これは、FluxでのGitOpsの整備の際にHelmの対応を後回しにしたためで、これらのコンポーネントのデプロイをHelmに置き換えることで生YAMLの変更の必要をなくしこのあたりの負担を軽くしたいと考えています。
また、現在はEKSクラスタの更新をInPlaceで行っているのですが、より安全にクラスタを更新できるようにするためBlue Greenでの更新を行うことも検討していきたいと考えています。
まとめ
転職会議では1年をかけてECSからEKSに移行してきました。そのなかで今後さらなる開発者体験の向上の試みを行っていく上で土台となるような基盤ができたと感じています。
一方で、EKS移行はあくまでスタートラインであり、Kubernetesの上で開発者がより使いやすくより障害が起きにくいインフラを求め改善を行っていくのはこれからが本番です。Kubernetes移行によって得られた「GitOpsに基づくCI/CDが行える環境」と「Kubernetesエコシステムで開発されたツールの採用の容易さ」をテコにさらなる改善を進めていきます。
We Are Hiring!
リブセンスではアプリケーション開発者を積極的に支えていけるようなインフラを一緒に作っていってくれるSREの仲間を募集しています。
SREを今までバリバリやってきた方に限らず、SREとして働くことに最近興味が湧いてきたアプリケーションエンジニアの方も大歓迎です。
カジュアル面談の場も用意していますので軽い気持ちで話を聞きに来てみてください!
また私個人のTwitterのDMでも「実際にリブセンスでSREって何をやっているのか」などいつでも質問に答えさせていただきますのでどうぞお気軽にお声がけください。