
こんにちは、転職会議のSREのかたいなかです。
転職会議のSREチームでは、現在SLOの導入に取り組んでいます。
最初の頃は、SLOに関しての知見がなかったこともあり導入の動きがドタバタになってしまい、今から考えるともっとうまく進められたなと思うことも多くありました。この記事ではそんな失敗も含めて記事にして共有します。
おさらい
SLI/SLO
- SLI(Service Level Indicator)とはシステムが提供しているサービスのレベルを計測するためのメトリクスのことです。
- SLO(Service Level Objective)とはSLIとして定められたメトリクスに対しての具体的な目標値のことです。
言葉で説明しても分かりづらいので以下に例をあげます。
例:
- ALB(AWSのL7ロードバランサ)の全レスポンスのうち2xxを返した割合(SLI)
- 1週間のうち99%のレスポンスは2xxであること(SLO)
- ワーカーで正常に処理できたレコードの割合(SLI)
- 1週間のうち99%のレコードが正常に処理されていること(SLO)
- レスポンスを99パーセンタイルが0.5秒以下だった時間帯の割合(SLI)
- 1週間のうち99%の時間帯で目標のレイテンシを達成していること(SLO)
事業の内容に応じてユーザの満足度をうまく数値化できるSLI/SLOを選ぶのがポイントです。
詳しくは参考資料で紹介している資料を参照ください。
エラーバジェット
SLOに基づいて損失が許容できるサービスレベルをエラーバジェットと呼びます。SLOを定義することで、バジェット(予算)として予め5xxエラーやレスポンスの悪化をどこまで許容するかが定義されるという考え方です。
エラーバジェットを使い果たした時(SLOに違反した時)にどうするかをエラーバジェットポリシーとして定めておくことで、日々の開発の中で、新規開発とサービスレベルの向上をどちらを優先するか数値ベースで議論できるようになります。
例えば、以下のようなエラーバジェットポリシーが考えられるでしょう。
- エラーバジェットを使い果たしたら、新機能のリリースを禁止し、品質の向上に集中する
- エラーバジェットを使い果たしたら、品質低下の原因となっている問題に次スプリントから優先的に取り組む。(新機能のリリースの禁止はしない)
こちらも詳しくは参考資料で紹介している資料を参照ください
転職会議での導入の目的
転職会議でSLOの導入を検討した動機は以下のような理由です
- 外部連携先からSLAの締結を求められた際の基準として使うため
- これが最初の動機でした
- パフォーマンスやエラー率等のデグレを検出するため
- 新規機能開発での品質のデグレ
- SRE以外の開発者が手動する大規模なマイグレーションでの品質のデグレ
- 例
- Elasticsearchのマイグレーション(ElasticCloud ⇒ Amazon ES)
- ReactやNext.jsのアップグレード
- バッチサーバのインフラ刷新(EC2上のcrontab ⇒ Kubernetes上のArgo Workflow)
- 例
- システムの高速化への取り組みを、個人の頑張りに依存することなく、組織の動きとして継続的に取り組んでいけるようにするため
具体的なSLI/SLO
転職会議では以下のようなSLI/SLOをDatadogのSLOの機能で設定しました。
フロントサーバ・APIサーバ
- インターネットに公開されているサーバ
- 1週間のうちALBで測定した99パーセンタイルのレイテンシがxxx秒以下である時間帯が90%以上であること
- 1週間のうちALBで測定した2xxを返すレスポンスの割合が99.5%以上であること。
- 内部向けAPI
- 1週間のうちDatadog APMで測定した99パーセンタイルのレイテンシがxxx秒以下である時間帯が90%以上であること
- 1週間のうちDatadog APMで2xxを返すレスポンスの割合が99.5%以上であること。
レイテンシの目標値に関しては、SEOの関係で低レイテンシが求められるサーバは厳しく、そうでないサーバは緩めに設定しました。
SLOをまずはシンプルに導入するため、レイテンシのSLIとしては99パーセンタイルのみ対象にしています。将来的には50パーセンタイル等も加えて様々なケースでの性能劣化をカバーできるようにしていきたいと考えています。
フロントエンド
フロントエンドではCore Web Vitalsに準拠して表示速度(ユーザ体験)をもとにSLOを設定しました。
すでに重要なページに対してLighthouseでLCPとCLSを定期的に測定する仕組みが整っていたので、これに対して目標値を設定しました。
- 1週間のうちLighthouseで測定したLCPがxxx秒を下回る時間帯の割合が90%以上であること
- 1週間のうちLighthouseで測定したCLSがxxxを下回る時間帯の割合が90%以上であること
新規開発時のデグレを検出できることを目標に、ページごとに現状の状態ベースでしきい値を設定しました。
フロントでのエラーレートに対してSLOを設定するのはこれからの課題です。
バッチ処理・キューワーカー(これから)
バッチ処理やキューワーカーに関しては処理の対象のレコードごとの成功率を計測するようにしようと考えています。
計測にはバッチ処理の成功/失敗のメトリクスが監視ツールで計測できる必要があります。バッチ処理の場合はアプリケーションコードに手を入れないとメトリクスを取得するのが難しそうなため、メール送信等、重要なバッチサーバから測定処理を導入していくことを考えています。(バッチ処理のSLOについて知見がある方いればぜひお話を聞かせてください)
進め方と仕組みづくり
実際にSLOを導入するにあたって意識したのは以下のような点です。
プロダクトオーナーと合意
SLOを導入すると、SLOを満たせていないときには新規開発よりも品質の向上を優先することになります。
そのため、まずプロダクトオーナーの方にSLOについて説明する場を設け、必要な場面では都度確認を取りながら進めるようにしました。
エラーバジェットポリシー
エラーバジェットを使い果たしたときにどうするかのルールをエラーバジェットポリシーとして定めました。
転職会議では、最初から少し厳しめのしきい値を最初から設定したこともあり、SLO違反時に新規リリースを禁止するのではなく、次のスプリントで問題箇所の解決に他の開発と並行して取り組んでもらうようにしました。
これにより、SLO導入当初からスプリントレビュー等でSLOの対応と新規開発の優先度を判断する機会が生まれ、結果的にSLOの動きの定着に良かったのではないかと考えています。
SLOダッシュボード
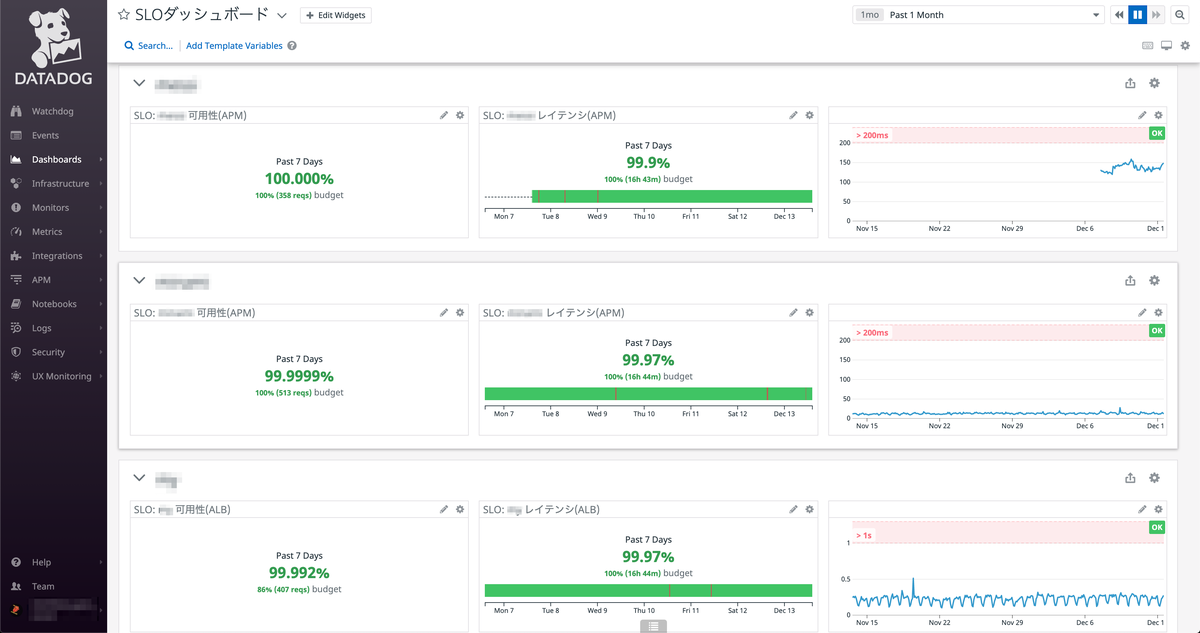
スクラムイベント等でSLOを振り返ることができるようにするため、各マイクロサービスに対してSLO関連の情報を表示する簡単な作りのSLOダッシュボードを用意しました。
エラーバジェット枯渇時のアラート
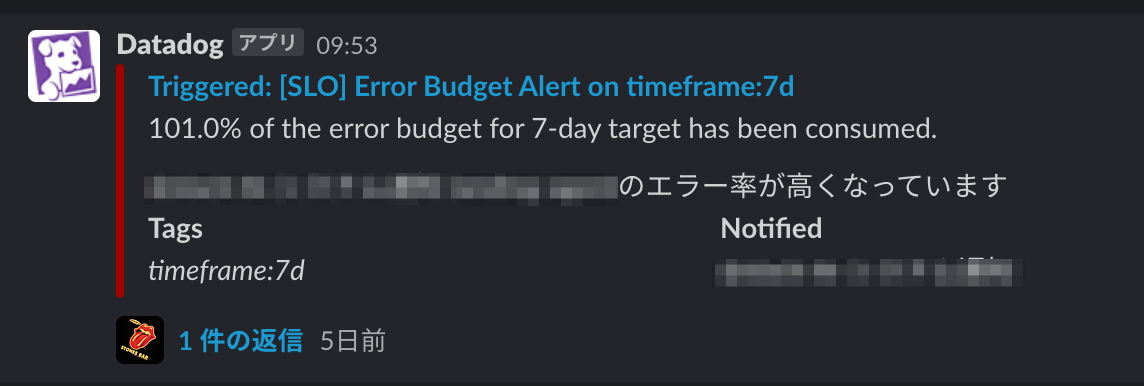
エラーバジェットが減少したときにアラートをSlackに飛ばすように設定しています。アラートが鳴ったときはリポジトリオーナーが問題を調査し、次スプリントで解決に取り組めるようIssueを作成する運用になっています。
DatadogのSLOには、現在のところエラーバジェットに基づいてアラートが実装されていない種類(monitor based)のものがありますが、これらについてはエラーバジェットを基準にしない普通のMonitorで代用する等しています。
振り返り
転職会議では2週間に一度各スクラムチームが集まり、成果を共有する「共同スプリントレビュー」というイベントを行っています。
共同スプリントレビューの場でSLOの準拠状況や品質向上の状況を振り返るようにしています。これにより、プロダクトオーナーにも現状の品質についての認識を持ってもらえるようにしています。
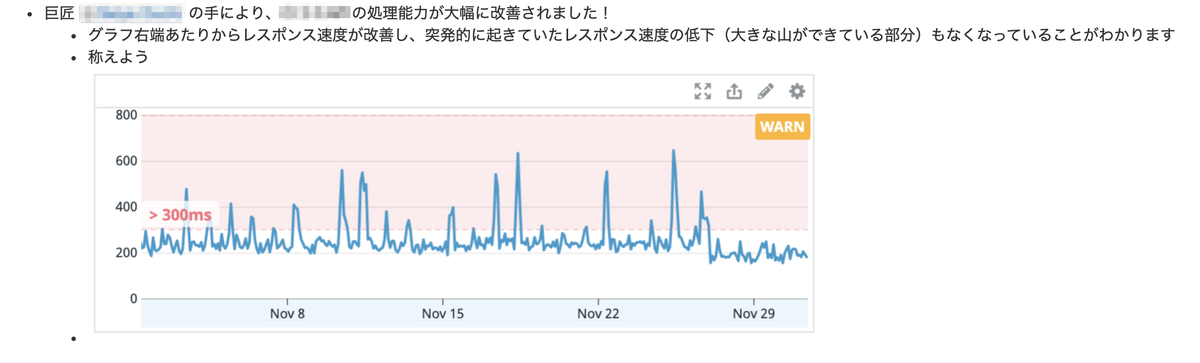
改善が行われた場合は少し大げさ目に改善内容を紹介し、SLOの文化醸成が促進されるように努めています。
SLOを入れてみて
よかったこと
SLOを導入してよかったと感じるのは以下のような点です
- パフォーマンスのデグレを拾えるようになった
- ElasticsearchのElasticCloudへの移行時に発生したパフォーマンス周りのデグレを拾えた。
- 5xxエラー発生時と同様にレイテンシの改善にも日々の開発の中で取り組めるようになった
- 改善を行う中でサーバサイドの改善がLCP等のフロントエンドのメトリクスの改善にもつながることも理解された
失敗したと感じること
SLOの導入を進めるにあたって失敗したと感じたのは以下のような点です。
- はじめてSLOのしきい値を決める際に厳しすぎるSLOを設定しようとしてしまった
- ゆるすぎるSLOの値を設定しても意味がないが、現状と乖離した厳しすぎるSLOを設定すると、いきなり大きめの対応をする必要が出て疲弊してしまう。
- SLOの導入と同時に改善タスクを実行する人的リソースを予め確保しておくのも手かもしれない。
- SREのなかで試しに回してみることをしなかった
- SLOの動きの全体像を定義して伝えることができなかったため混乱した
- なぜやるのか?が明確なメッセージとして伝えられなかった
- Datadogのダッシュボードの作成やアラートの設定等、技術的な細かい部分に拘りすぎてSLO導入の動きがスピードダウンしてしまった
- きれいなダッシュボードを作ることよりも、SLOを満たせなかったときにどういう動きをするのか等、動き方を設計することのほうがずっと重要。
これからやっていきたいこと
定期的なSLOの振り返り・見直し
一般的な監視の設定と同様に、SLOを導入当時のまま放っておくとどんどん腐っていきます。SLOのしきい値が現状と乖離し、またSLOでカバーしている範囲が事業の内容とずれたままになっていきます。また、SLOを運用して得られた知見をSLOに反映させることもできません。
SLOを定期的に見直すことでSLIやしきい値を定期的に改善し、ユーザの満足度やシステムの現状に見合った状態であり続けるようにしたいと考えています。
カナリアリリース(SLOを支えるCI/CD)
カナリアリリースは、新しくデプロイするサーバに流すトラフィックの割合を順番に増やしていくデプロイ方法です。新しいサーバに流れるトラフィックが増えていく中で、問題が検出された場合には自動でロールバックすることでエラーバジェットの消費を節約することができます。
現在はナイーブなローリングアップデートによるデプロイを行っていますが、将来的にはカナリアリリースを導入したいと考えています。
最後に
SLOはどちらかというと技術よりも組織の動き方に重点がある取り組みのため、始めた当初はどう進めていいか悩むことが多くあり、個人的にも学びの大きい取り組みでした。
転職会議での事例が他のSLOの導入を検討されている方に役立てば幸いです。
We Are Hiring!
リブセンスではSLO等の新しい考え方の導入に一緒に取り組んでくれるSREの仲間を募集しています。
SREを今までバリバリやってきた方に限らず、SREとして働くことに最近興味が湧いてきたアプリケーションエンジニアの方も大歓迎です!
カジュアル面談の場も用意していますので軽い気持ちで話を聞きに来てみてください!
また私個人のTwitterのDMでも「実際にリブセンスでSREって何をやっているのか」などいつでも質問に答えさせていただきますのでどうぞお気軽にお声がけください。