
こんにちは、かたいなかです。
最近、転職会議のあるサーバで発生していたメモリリークについて調査する機会がありました。 今回の記事ではメモリリークをどのように調査したか等をまとめます。
⚠️:2024/10/21追記
- 当初、デフォルトですべてのrakeタスクに対しての計装が有効と記載していました。しかし、実際にそのような挙動をするのはdd-trace-rbがv1.3.0より前のバージョンの場合のようです。それ以降のバージョンでは計装するrakeタスクを明示的に指定する必要があるため、デフォルト値に起因する設定ミスが起きにくくなっているようです。
- はてなブックマークのコメントで教えていただいた、部分フラッシュのオプションについての記述を追加しました。
TL;DR
- 長時間稼働するrakeタスクのDatadog APMによる計装は避けましょう。
- rakeタスク内の処理でのspanが、rakeタスクを親とするトレースに追加され続け、メモリの使用量が大きくなってしまうためです。
- どうしても長時間稼働するrakeタスクを計測したい場合は、
c.tracing.partial_flush.enabled = trueというオプションを使用すること。
- どうしても長時間稼働するrakeタスクを計測したい場合は、
- dd-trace-rbのv1.3.0より前のバージョンではrakeの計装がすべてのrakeタスクに対してデフォルトで有効なので注意。
- rakeタスク内の処理でのspanが、rakeタスクを親とするトレースに追加され続け、メモリの使用量が大きくなってしまうためです。
状況
転職会議のとあるサーバで、使用しているメモリの量が継続的に増加していき、最終的にメモリが枯渇してサーバが再起動される問題が起きていました。
以下は、メモリ使用量のグラフです。

メモリリークが起きていたサーバは、SQSからメッセージをポーリングし、メッセージの内容をもとにDBに処理を行うワーカーでした。
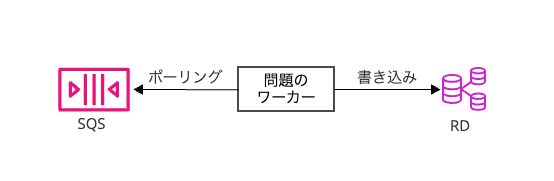
処理を行っていた部分のコードを簡略化したものが以下です。
task :worker do poller = Aws::SQS::QueuePoller.new(queuer_url) poller.poll(skip_delete: true, max_number_of_messages: 10) do |messages| result = process_messages(messages) poller.delete_messages(messages) rescue StandardError => e # 略 next end end
コードを見てわかるように、特殊な処理は特に行っておらず、メモリリークの原因になりそうなコードは見当たらない状況でした。
調査
当時は何もわからなかったので、まずは計測のためmemory-profilerを仕込んでステージング環境で動かしてみることにしました。
以下のようにmemory-profilerを仕込んでステージング環境で動かしました。
task :worker do poller = Aws::SQS::QueuePoller.new(queuer_url) poller.poll(skip_delete: true, max_number_of_messages: 10) do |messages| report = MemoryProfiler.report do result = process_messages(messages) # メッセージを元にDBに処理を行う poller.delete_messages(messages) end report.pretty_print rescue StandardError => e # 略 next end end
以下のように、memory-profilerによって出力された情報を見ると、Datadog APMに関するオブジェクトが保持されていることがわかりました。
/*略*/ retained objects by class ----------------------------------- /*略*/ 7 Datadog::Tracing::Span 3 Datadog::Tracing::SpanOperation 3 Datadog::Tracing::SpanOperation::Events 3 Datadog::Tracing::SpanOperation::Events::AfterFinish 3 Datadog::Tracing::SpanOperation::Events::AfterStop 3 Datadog::Tracing::SpanOperation::Events::BeforeStart /*略*/
Datadog APM関連のオブジェクトが保持されていることが気になったのは、このサーバのトレース情報はDatadog APMに送られてきていなかったからです。memory-profilerを見るまではDatadog APMが無効化されているものだとすら思い込んでいました。
そこで、Datadog APM関連の設定を見てみると、以下のような設定がありました。
Datadog.configure do |c| c.tracing.enabled = Rails.env.production? || Rails.env.staging? c.agent.host = "<host>" c.service = "<service-name>" c.env = Rails.env c.tracing.instrument :rails, { service_name: "<service-name>" } end
一見すると正しい設定に見えます。
しかし、Datadog APMにトレース情報が送られていないため、何か問題が起きているのは間違いありません。
そこでDatadog APMのドキュメントを読み込んでみることにしました。
すると、rakeタスクの計装のところで気になる記述をいくつか見つけることができました。
まず気になったのは、rakeの計装は設定を明示的に行わなくても自動で有効になることです。 (enabled のデフォルトが true)
⚠️:2024/10/21追記 デフォルトですべてのrakeタスクに対しての計装が有効になるのはdd-trace-rbがv1.3.0より前のバージョンの場合のようです。それ以降のバージョンでは計装するrakeタスクを明示的に指定する必要があるようです。 github.com
そして、次に気になったのは以下の記述です。
長時間稼働する Rake タスクのインスツルメンテーションは避けてください。そのようなタスクは、タスクが終了するまで決してフラッシュされない、メモリ内の大きなトレースを集計する場合があります。
今回はワーカーをrakeタスクで起動しており、メモリリークが発生していました。まさに今回のケースに当てはまっているように見えます。
そこで、追加調査として、以下のようなコードでアクティブなspanを取得してみることにしました。
pp Datadog::Tracing.active_span
すると、予想通りrakeのspanがアクティブになっていました。
長時間稼働する Rake タスクを計装してしまっていたのが原因で間違いなさそうです。
改修
ここまでで分かったことをもとに、Datadog APM関連のコードの修正を行いました。
まず、rakeの計装は無効化しました。
c.tracing.instrument :rake, { enabled: false }
代わりに、SQSのポーリング単位でトレースを取得するようにしました。
task :worker do poller = Aws::SQS::QueuePoller.new(queuer_url) poller.poll(skip_delete: true, max_number_of_messages: 10) do |messages| Datadog::Tracing.trace("worker.process.something") do result = process_messages(messages) poller.delete_messages(messages) end rescue StandardError => e # 略 next end end
このコードをリリースすると、メモリ使用率の継続的な増加はなくなりました!🎉🎉🎉

また、Datadog APMにも適切にデータが送られるようになりました。
2024/10/21 追記: どうしても長時間稼働するrakeタスクを計測したい場合はどうするか
バッチ処理などで、どうしても長時間稼働するrakeタスクを計測したい場合もあるかと思います。その場合どうしたら良いでしょうか?
1つの方法として、以下のような設定で部分フラッシュを有効化する方法があるようです。
tracing.partial_flush.enabled = true
これにより、rootスパンの終了を待つことなく、一定の量のスパンが溜まったら送信してくれるようです。
ただし、サンプリングロジックの関係で微妙な問題が起こることがあるようです。 詳細は以下のIssueコメントを参照ください。
はてなブックマークでこちらの方法を教えていただいた、kompiroさん、ありがとうございます。
Datadog APMの設定ミスのせいでメモリリークしていた話 - LIVESENSE ENGINEER BLOGb.hatena.ne.jpdatadog gem は tracing.partial_flush.enabled が false がdefaultなので長期実行されるjobだとたまり続けるからその話なんじゃないかと思った。
2024/10/20 00:03
まとめ
謎のメモリリークを調査したら、Datadog APMのライブラリを不適切に設定していたことが原因だったという事例について紹介しました。
今回は、memory-profilerなどで計測を行ったことで糸口が得られ、解決につなげることができました。
メモリリークやパフォーマンスバグなどの比較的難しいバグの対応を行うときには、無闇矢鱈に想像できる設定値を変更して試したりしたくなりがちです。
しかし、原因が想像の範囲外にある場合には、そのような変更が徒労に終わってしまうことも多いです。
そのため、まずは計測を行い(意図的に計測しなくてもすでに計測ができているのがベスト)、正しく計測結果を読んで、可能性の高そうな仮説を立てることを意識して取り組むようにしましょう。
参考
補足: なぜDatadog Continuous Profilerでないか
以前、記事でDatadog Continuous Profilerを紹介しました。
今回はContinuous Profilerによる調査を行わなかった事情を補足します。
今回のケースでは、Datadog APMが動いていないつもりで調査を開始したため、APMといっしょに動くContinuous Profilerはツールとして選択しませんでした。
結果的にDatadog APMが実は動いていたのですが、Datadogに情報を正しく送れていなかったため、Datadog APMが動いていても使えなかったのではないかと考えています。
編集履歴
- 2024/10/18 初版
- 2024/10/21 以下の内容について編集・追記
- 部分フラッシュのオプションについて
- dd-trace-rbのv1.3.0以降では指定したrakeタスクのみ計装されること